The Learning Problem
Learning:
A computer program is said to learn from experience \(E\) with respect to some class of tasks \(T\) and performance measure \(P\), if its performance at tasks in \(T\), as measured by \(P\), improves with experience \(E\).
-
The Basic Premise/Goal of Learning:
“Using a set of observations to uncover an underlying process”
Rephrased mathematically, the Goal of Learning is:
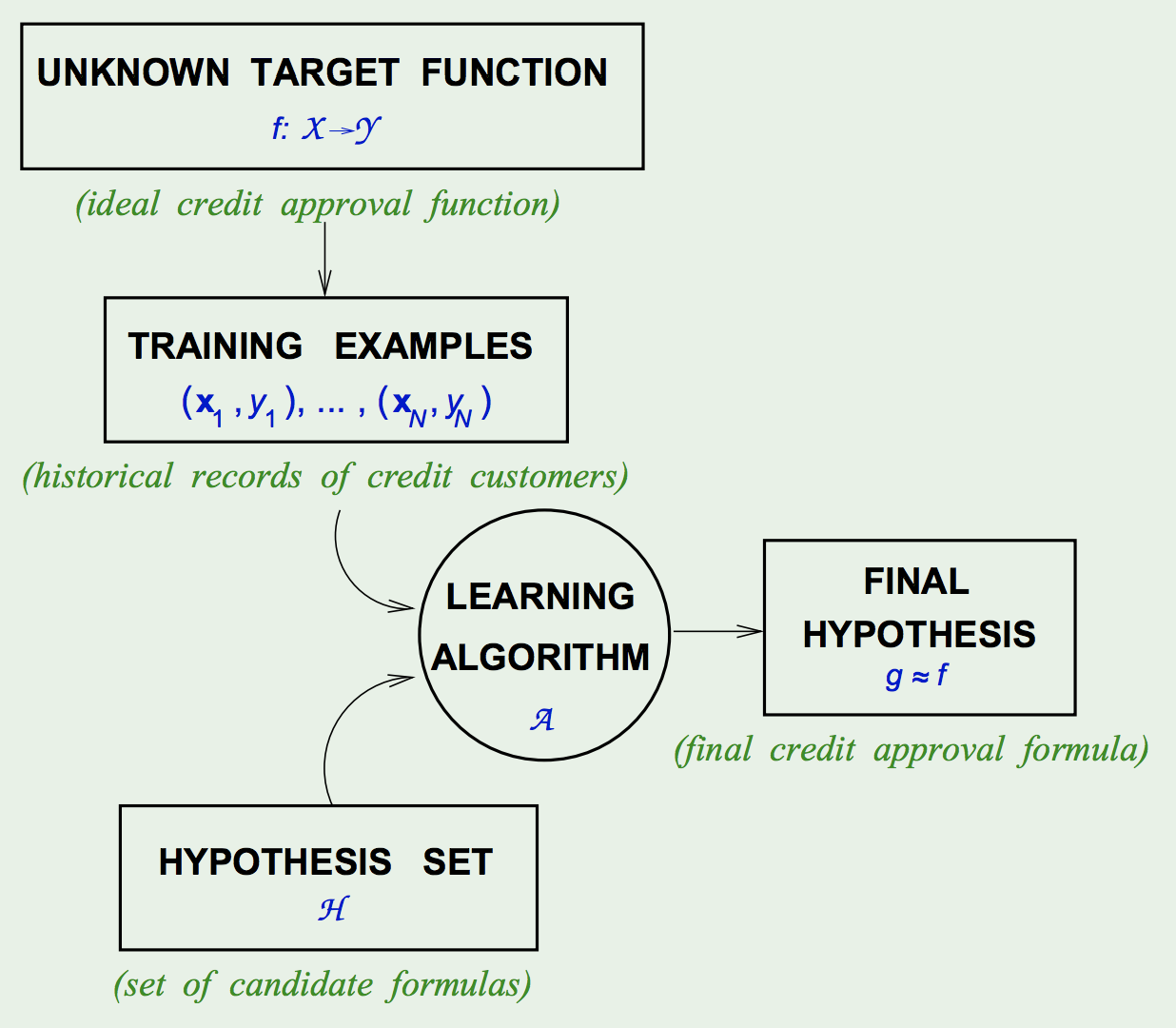
Use the Data to find a hypothesis \(g \in \mathcal{H}\), from the hypothesis set \(\mathcal{H}=\{h\}\), that approximates \(f\) well. - When to do Learning:
When:- A pattern Exists
- We cannot pin the pattern down mathematically
- We have Data
- Components of the Problem (Learning):
- Input: \(\vec{x}\)
- Output: \(y\)
- Data: \({(\vec{x}_ 1, y_ 1), (\vec{x}_ 2, y_ 2), ..., (\vec{x}_ N, y_ N)}\)
- Target Function: \(f : \mathcal{X} \rightarrow \mathcal{Y}\) (Unknown/Unobserved)
- Hypothesis: \(g : \mathcal{X} \rightarrow \mathcal{Y}\)
- Components of the Solution:
- The Learning Model:
- The Hypothesis Set: \(\mathcal{H}=\{h\}, g \in \mathcal{H}\)
E.g. Perceptron, SVM, FNNs, etc.
- The Learning Algorithm: picks \(g \approx f\) from a hypothesis set \(\mathcal{H}\)
E.g. Backprop, Quadratic Programming, etc.
- The Hypothesis Set: \(\mathcal{H}=\{h\}, g \in \mathcal{H}\)
- The Learning Model:
-
The Learning Diagram:
- Types of Learning:
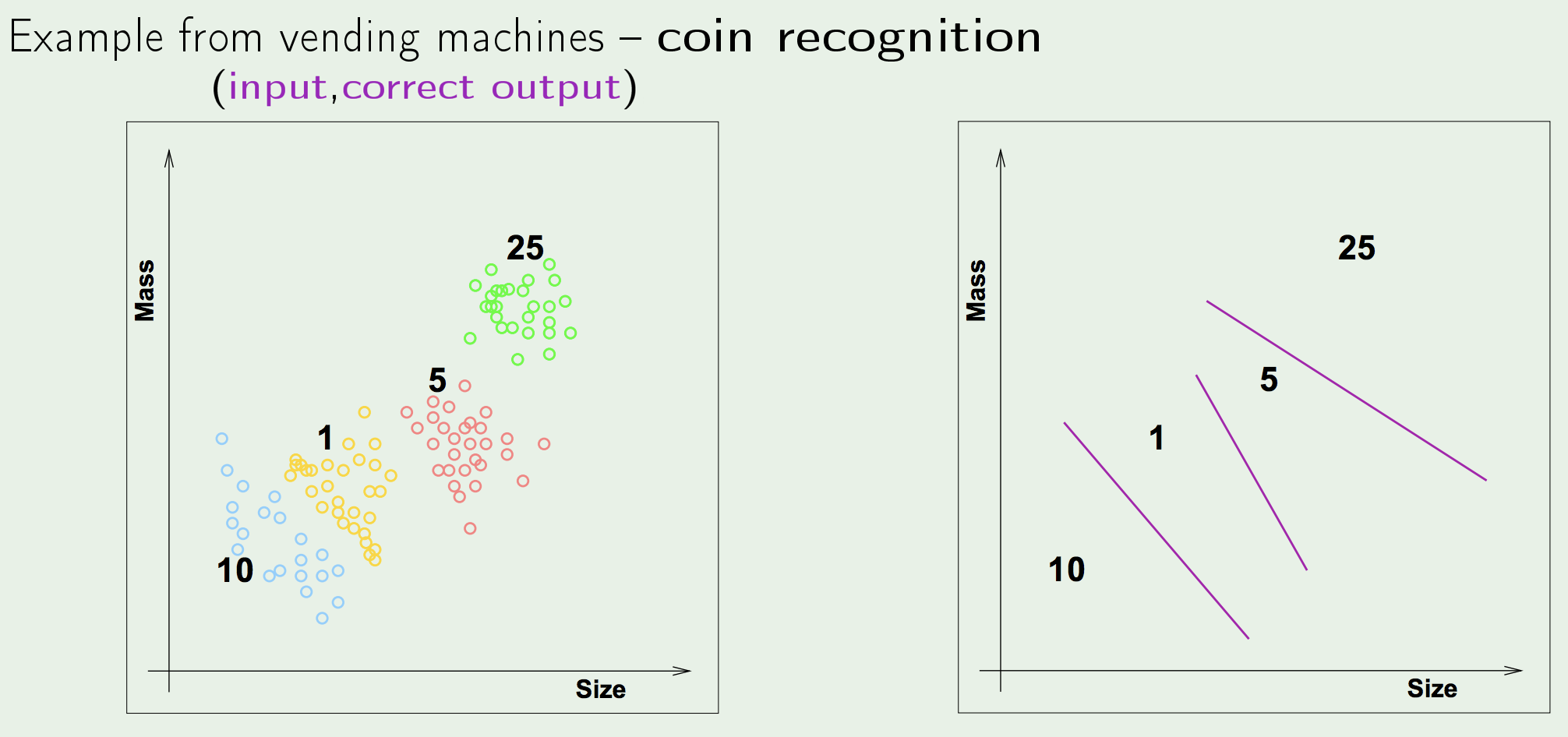
- Supervised Learning: the task of learning a function that maps an input to an output based on example input-output pairs.
- Unsupervised Learning: the task of making inferences, by learning a better representation, from some datapoints that do not have any labels associated with them.
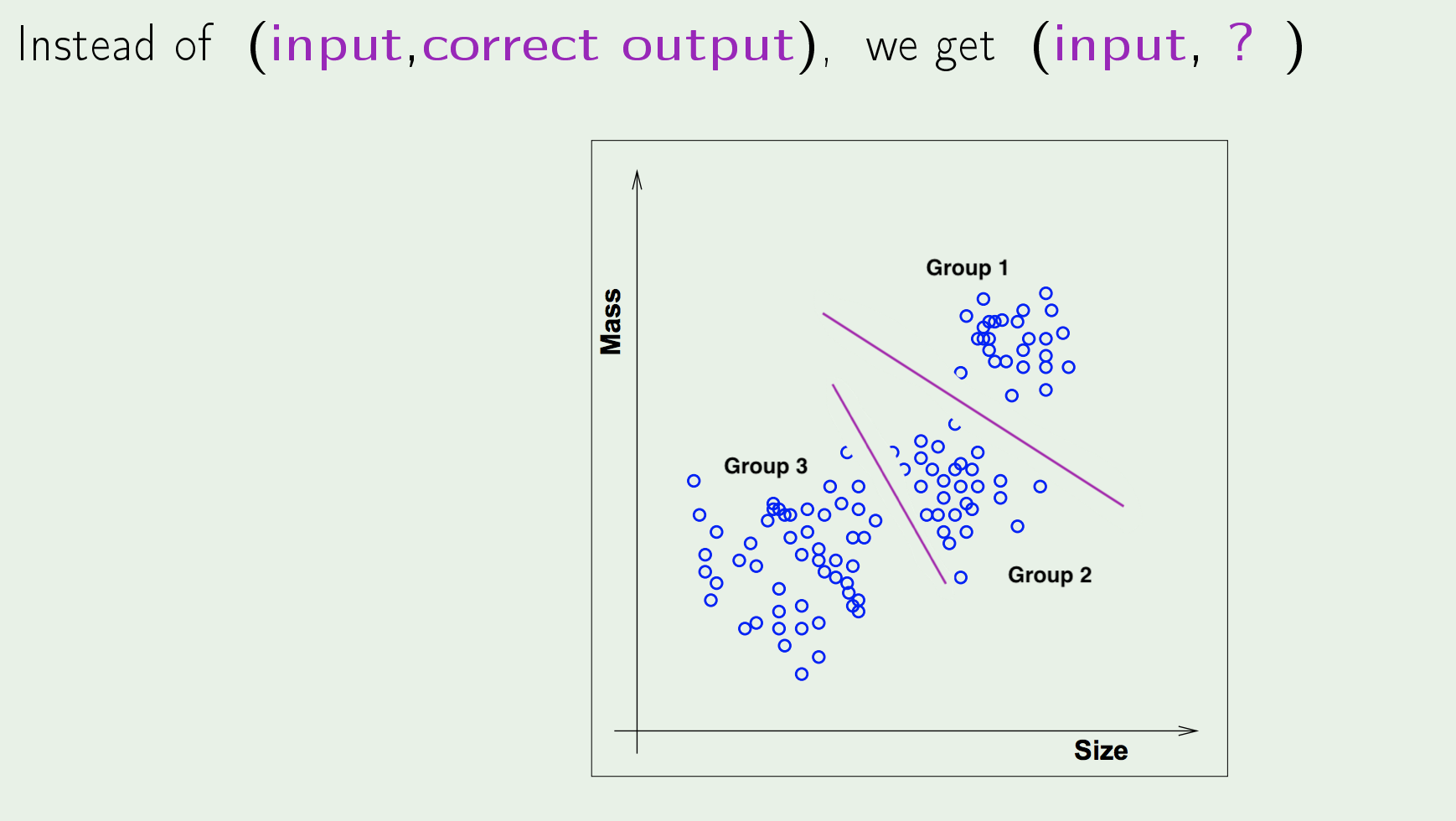
Unsupervised Learning is another name for Hebbian Learning
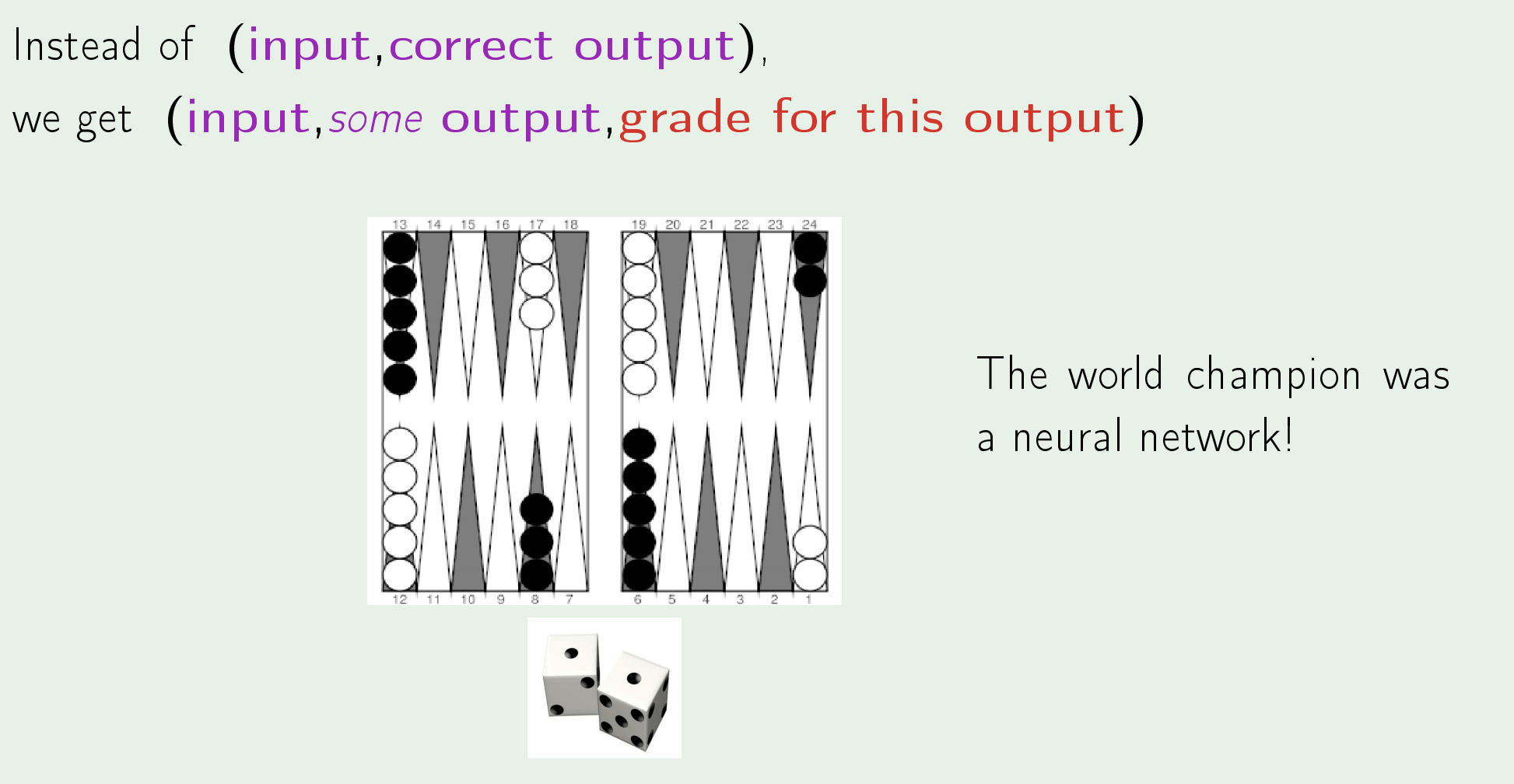
- Reinforcement Leaning: the task of learning how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.
- Supervised Learning: the task of learning a function that maps an input to an output based on example input-output pairs.
The Feasibility of Learning
The Goal of this Section is to answer the question:
“Can we make any statements/inferences outside of the sample data that we have?”
-
The Problem of Learning:
Learning a truly Unknown function is Impossible, since outside of the observed values, the function could assume any value it wants. -
Learning is Feasible:
The statement we made that is equivalent to Learning is Feasible is the following:
We establish a theoretical guarantee that when you do well in-sample \(\implies\) you do well out-of-sample (“Generalization”) .Learning Feasibility:
When learning we only deal with In-Sample Errors \(E_{\text{in}}(\mathbf{w})\); we never handle the out-sample error explicitly; we take the theoretical guarantee that when you do well in-sample \(\implies\) you do well out-sample (Generalization). -
Achieving Learning:
Generalization VS Learning:
We know that Learning is Feasible.- Generalization:
It is likely that the following condition holds:$$\: E_{\text {out }}(g) \approx E_{\text {in }}(g) \tag{3.1}$$
This is equivalent to “good” Generalization.
- Learning:
Learning corresponds to the condition that \(g \approx f\), which in-turn corresponds to the condition:$$E_{\text {out }}(g) \approx 0 \tag{3.2}$$
How to achieve Learning:
We achieve \(E_{\text {out }}(g) \approx 0\) through:- \(E_{\mathrm{out}}(g) \approx E_{\mathrm{in}}(g)\)
A theoretical result achieved through Hoeffding PROBABILITY THEORY . - \(E_{\mathrm{in}}(g) \approx 0\)
A Practical result of minimizing the In-Sample Error Function (ERM) Optimization .
Learning is, thus, reduced to the 2 following questions:
- Can we make sure that \(E_{\text {out }}(g)\) is close enough to \(E_{\text {in }}(g)\)? (theoretical)
- Can we make \(E_{\text {in}}(g)\) small enough? (practical)
- Generalization: