(
- It is extremely hard to learn a model of the world without experiencing “enough examples”, so the data is still extremely necessary.
-
To capture an entire distribution over some data that should GENERALIZE well; is limited by how actually representative that data is of the true “data-generating” distribution, so “good” data is necessary )
- Hypothesis: Deep CNNs have a tendency to learn superficial statistical regularities in the dataset rather than high level abstract concepts.
- From the perspective of learning high level abstractions, Fourier image statistics can be superficial regularities, not changing object category.
- So long as our machine learning models cheat, by relying only on superfcial statistical regularities, they remain vulnerable to out-of-distribution examples.
- Humans generalize better than other animals thanks to a more accurate internal model of the underlying causal relationships.
The need for predictive causal modeling: rare & dangerous states:
- Autonomous vehicles in near- accident situations.
- Current supervised learning fails these cases because they are too rare.
- Worse with RL (statistical inefficiency)
- Goal: develop better predictive models of the world able to generalize in completely unseen scenarios, but it does not seem reasonable to model the sequence of future states in all their details.
- (Without) No need to die a thousand deaths
Motivation:
- As we are deploying Machine Learning in the real world, what happens is that, the kind of data on which those systems will be used, is almost for sure are going to be statistically different from the kind of data on which it was trained.
- And as an example of this consider self driving cars or vehicles, for which would like them to behave well in these rare but dangerous states.
Invariance vs Disentangling:
- They are different concepts.
- Invariance: is a property of an object/system being equal wrt. a certain change.
We seek to have invariant detectors, features, etc. to certain things we care about; but sensitive to other things (based on the domain). - Disentangling:
- Motivation:
- But if we’re trying to explain the world around us, if we’re trying to build machines that explain the world around them that understand their environment, we should be prudent about what aspects of the world we would like our systems to be invariant about. Maybe we want to capture everything.
And the most important aspect isn’t what we get rid of or not, but rather how we can separate the different factors from each other. - It helps us deal with curse of dimensionality.
- But if we’re trying to explain the world around us, if we’re trying to build machines that explain the world around them that understand their environment, we should be prudent about what aspects of the world we would like our systems to be invariant about. Maybe we want to capture everything.
- Motivation:
-
Good Representations (Bengio)
The idea is when we transform the data in the space, machine learning becomes easier.
So, in particular, the kind of complex dependencies that we see in them, say, the pixel space will become easy to model maybe with linear models or factorize models in that space. - Latent Variables and Abstract Representations
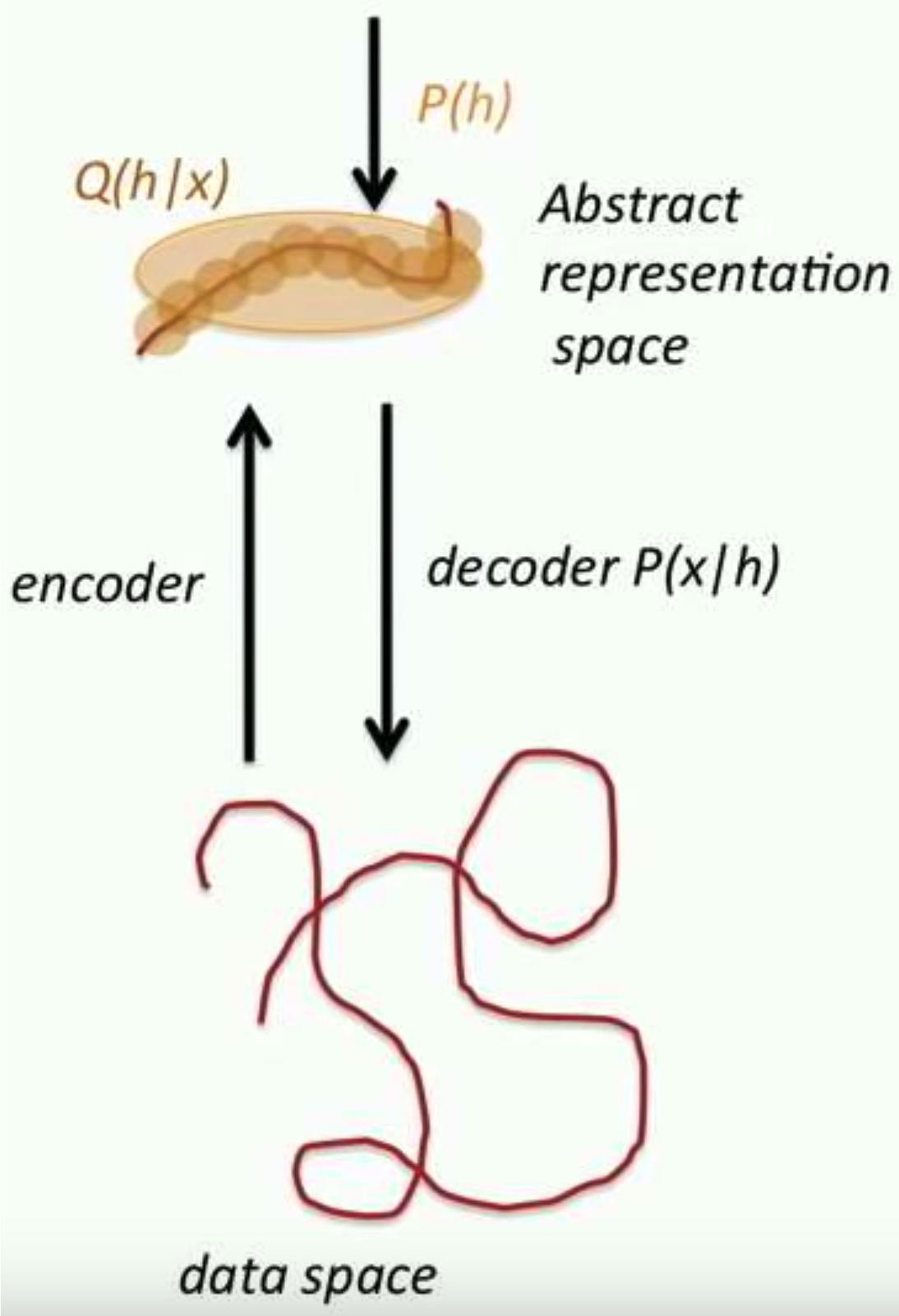
- Encoder/decoder view: maps between low \(\&\) high-levels
- Encoder does inference: interpret the data at the abstract level
- Decoder can generate new configurations
- Encoder flattens and disentangles the data manifold
Go from a “spaghetti” of manifolds to, flat and separate manifolds.- A big goal is: transform the “curved” (data) manifold, into a flat manifold.
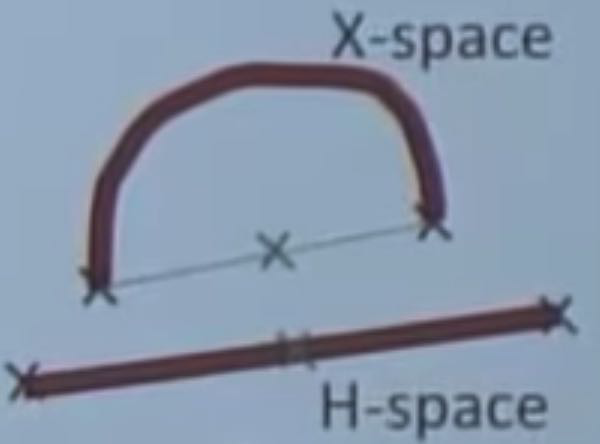
- Checking that a manifold is flat:
Simple Idea: Interpolate between two points on the manifold (average), if the middle point comes from the data distribution (e.g. image), then it is flat.- Interpolating in h-space should give you e.g. either one image or the other, but not a blend (preserve identity).
- Interpolating in X-space will give you e.g. a combination of the two images.
-
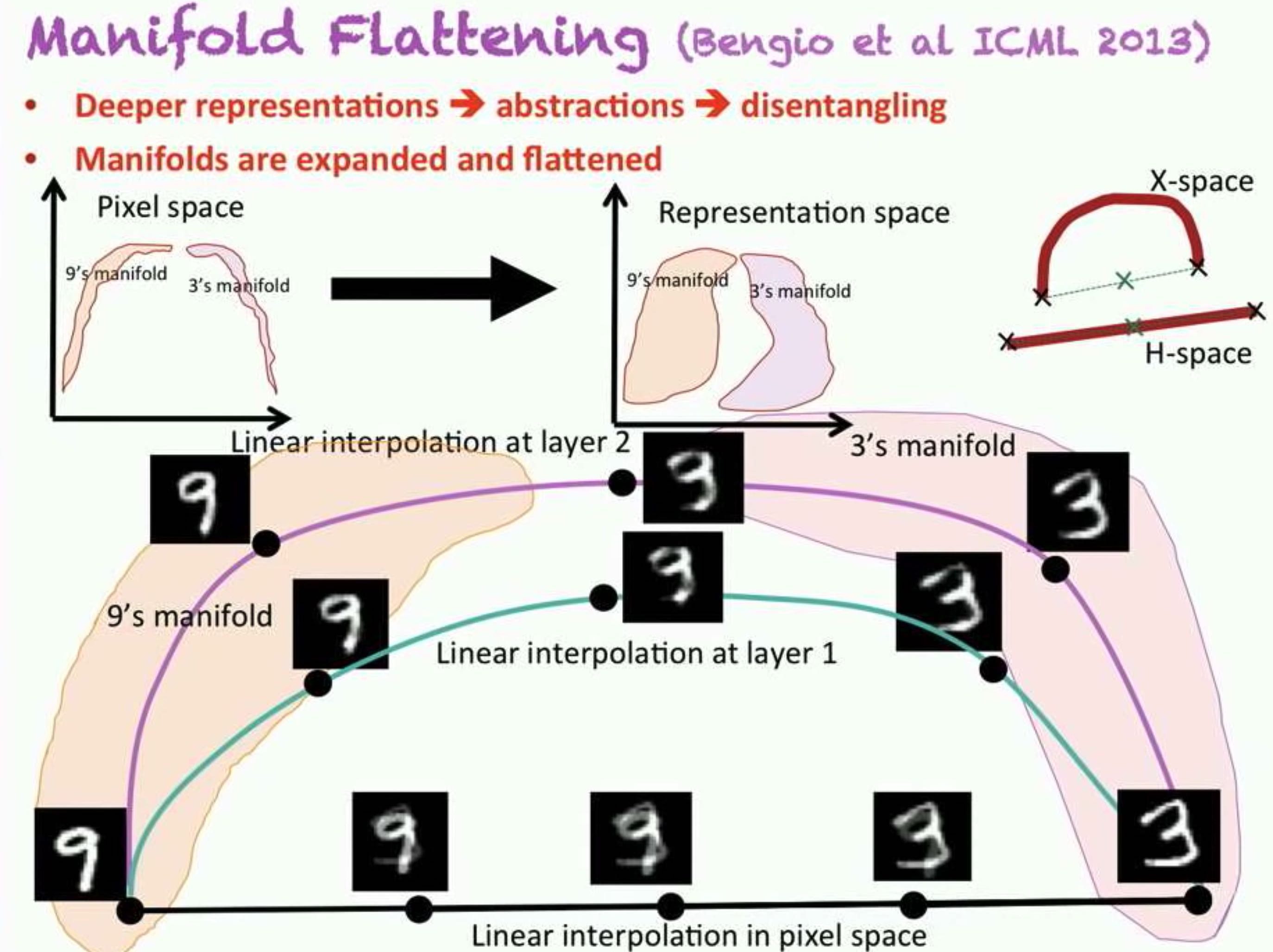
- A big goal is: transform the “curved” (data) manifold, into a flat manifold.
- Marginal independence in h-space
- What’s missing in DL:
Deep Understanding. - What is needed:
- Generalizing Beyond i.i.d. Data:
- The Learning Theories need to be modified.
- Current ML theory is strongly dependent on the iid assumption
- Real-life applications often require generalizations in regimes not seen during training
- Humans can project themselves in situations they have never been (e.g. imagine being on another planet, or going through exceptional events like in many movies)
- Solution: understanding explanatory/causal factors and mechanisms.
- How: Clues to help disentangle the underlaying causal factors (w/ regularization).
- Generalizing Beyond i.i.d. Data:
- Humans Outperform Machines at Autonomous Learning:
- Humans are very good at unsupervised learning, e.g. a 2 year old knows intuitive physics
- Babies construct an approximate but sufficiently reliable model of physics.
- How do they manage that?
Note that they interact with the world, not just observe it.- It is important to act in the world to acquire information.
The basic tools for that come from RL.
It is not developed enough, as of now.Note: the information gained/learned by an acting agent is subjective to his own capabilities/affordences.
E.g. Adult vs Baby (bodies) interacting with the world.
- It is important to act in the world to acquire information.
- How do they manage that?