LeNet-5: (LeCun et al., 1998)
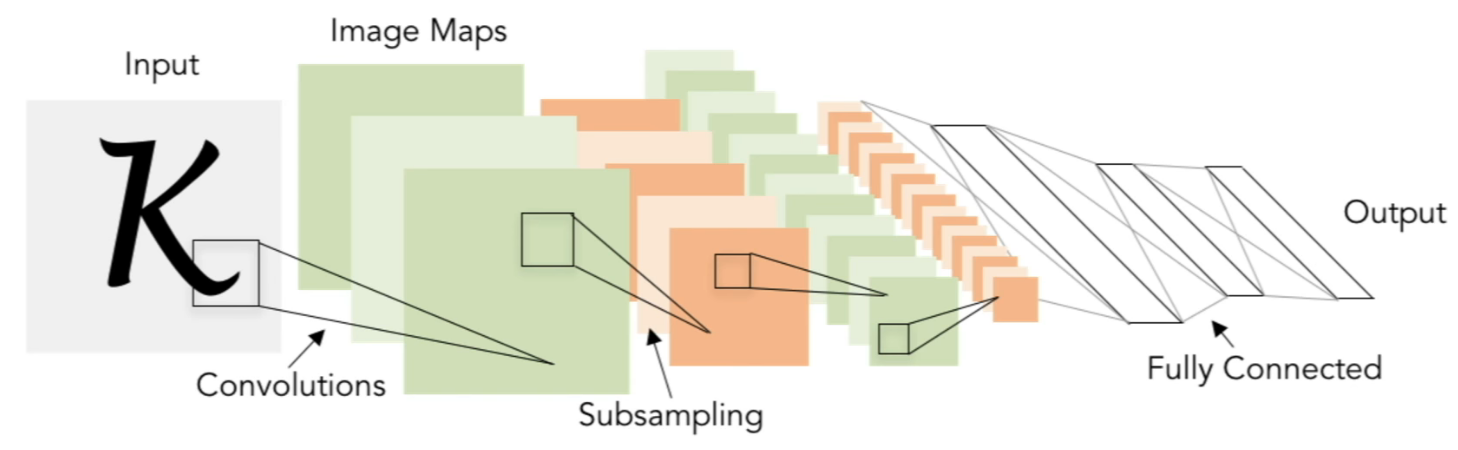
- Architecture: [CONV-POOL-CONV-POOL-FC-FC]
- Parameters:
- CONV: F=5, S=1
- POOL: F=2, S=2
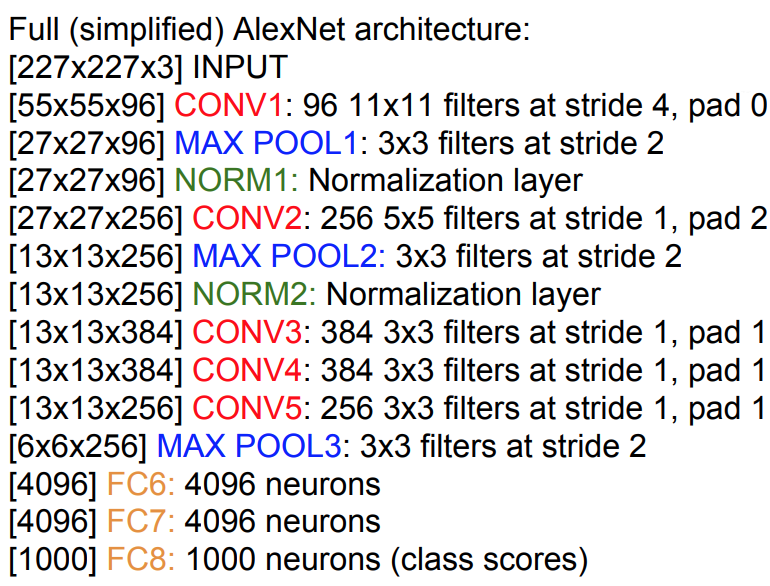
AlexNet (Krizhevsky et al. 2012)
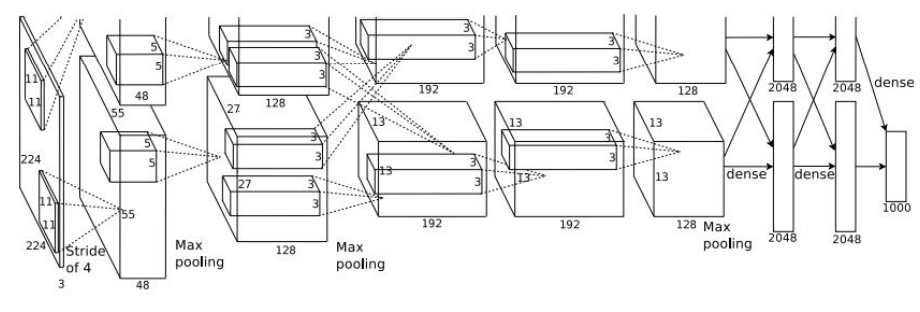
-
- Architecture:
- [CONV1-MAX-POOL1-NORM1-CONV2-MAX-POOL2-NORM2-CONV3-CONV4-CONV5-Max-POOL3-FC6-FC7-FC8]
-
- Parameters:
-
- First Layer (CONV1):
- F: second
- First Layer (CONV1):
-
- Key Insights:
-
- first use of ReLU
- used Norm layers (not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% -> 15.4%
-
- Results:
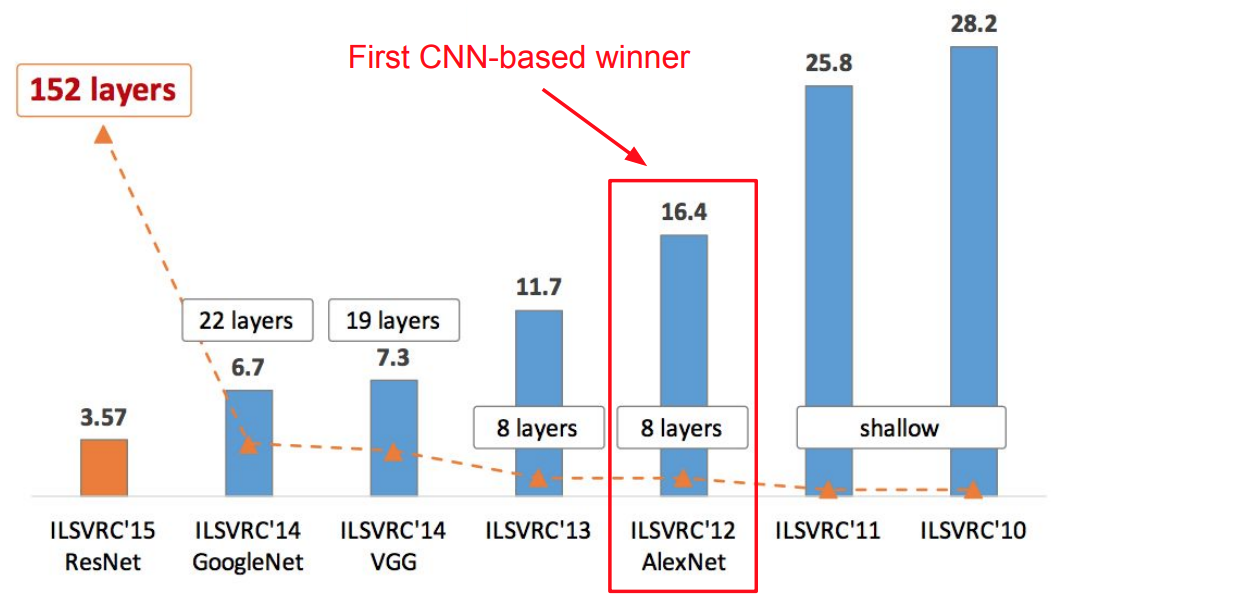
-
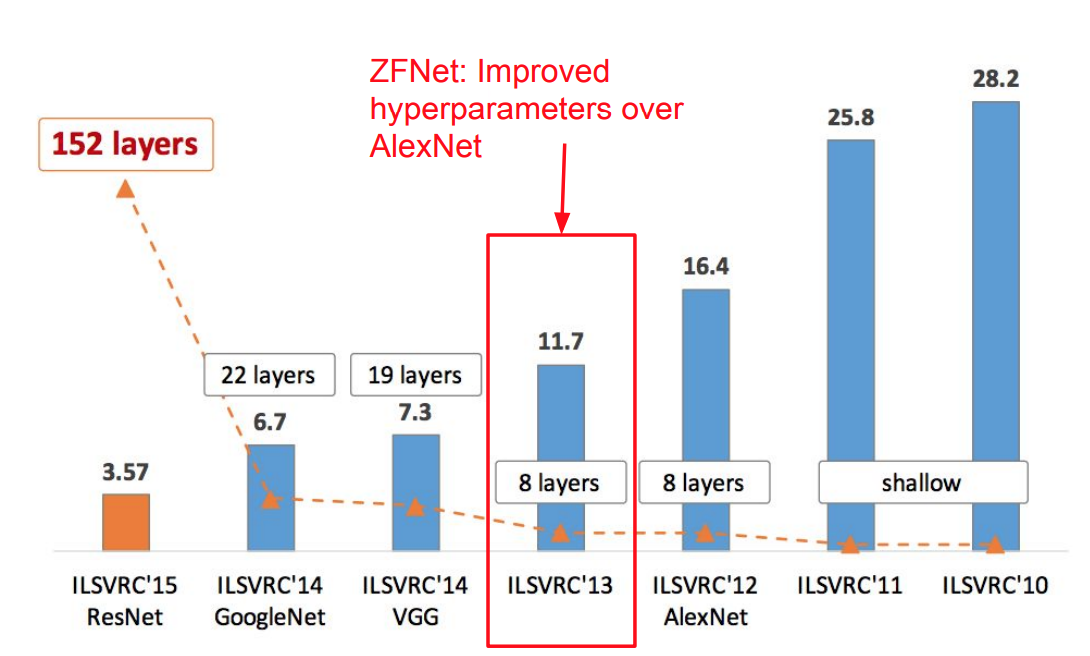
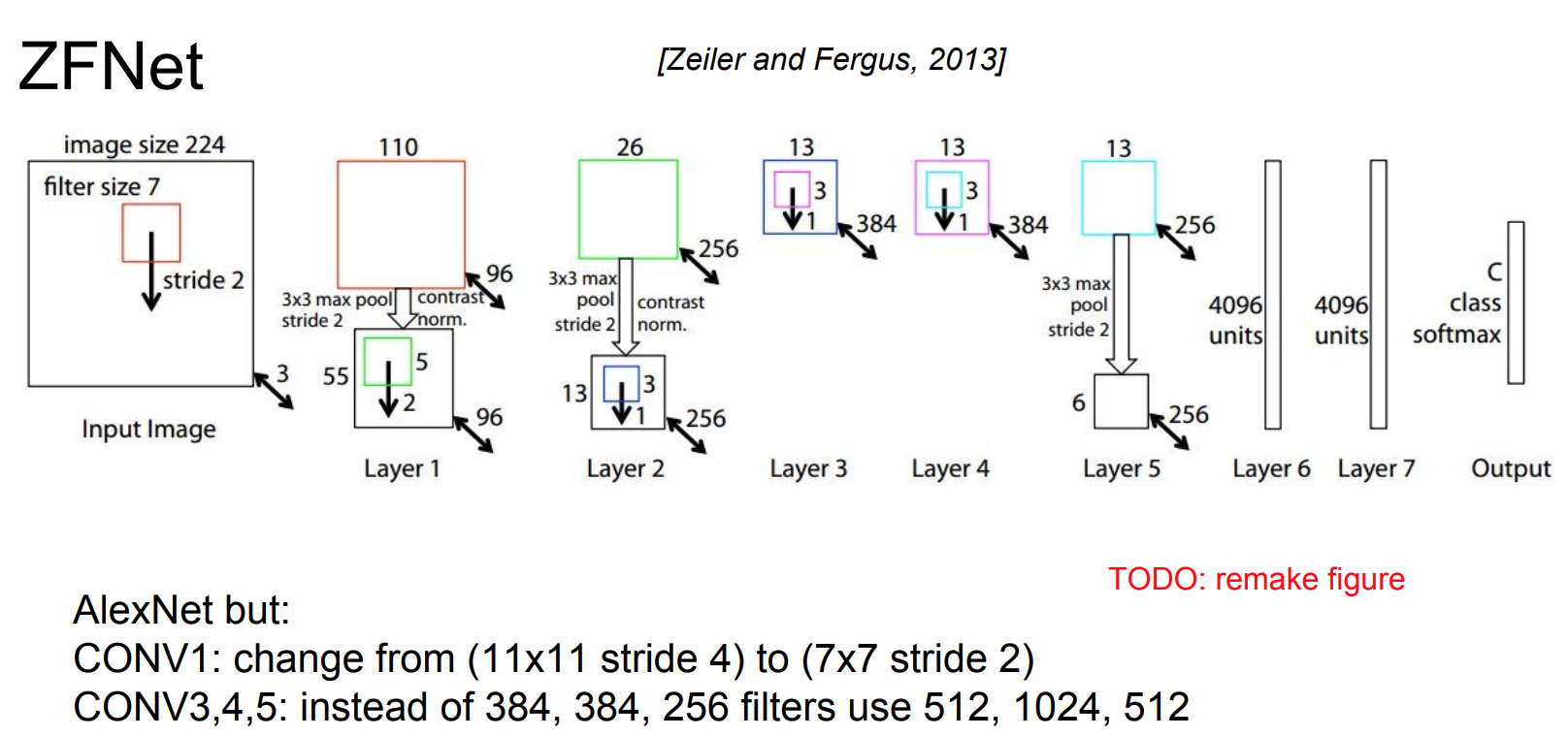
- ZFNet (Zeiler and Fergus, 2013):
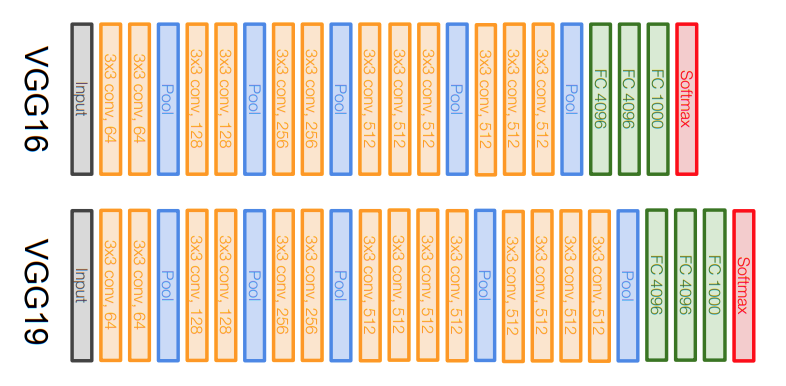
VGGNet (Simonyan and Zisserman, 2014)
-
- Parameters:
-
- CONV: F=1, S=1, P=1
- POOL: F=2, S=2
For all layers

-
Notice:
Parameters are mostly in the FC Layers
Memory mostly in the CONV Layers
-
- Key Insights:
-
- Smaller Filters
- Deeper Networks
- Similar Training as AlexNet
- No LRN Layer
- Both VGG16 and VGG19
- Uses Ensembles for Best Results
-
- Smaller Filters Justification:
-
- A Stack of three 3x3 conv (stride 1) layers has same effective receptive field as one 7x7 conv layer
- However, now, we have deeper nets and more non-linearities
- Also, fewer parameters:
3 * (3^2C^2 ) vs. 7^2C^2 for C channels per layer
-
- Properties:
-
- FC7 Features generalize well to other tasks
-
- VGG16 vs VGG19:
- VGG19 is only slightly better and uses more memory
-
- Results:
- ILSVRC’14 2nd in classification, 1st in localization
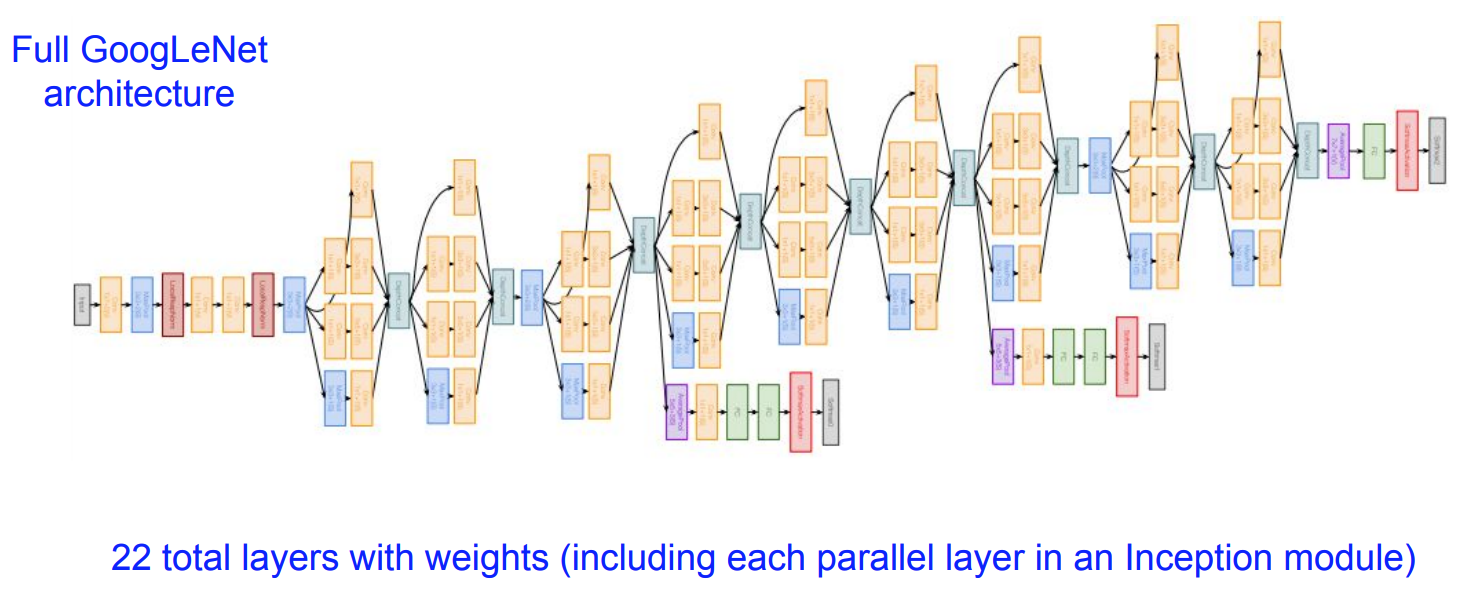
GoogLeNet (Szegedy et al., 2014)
-
- Architecture:
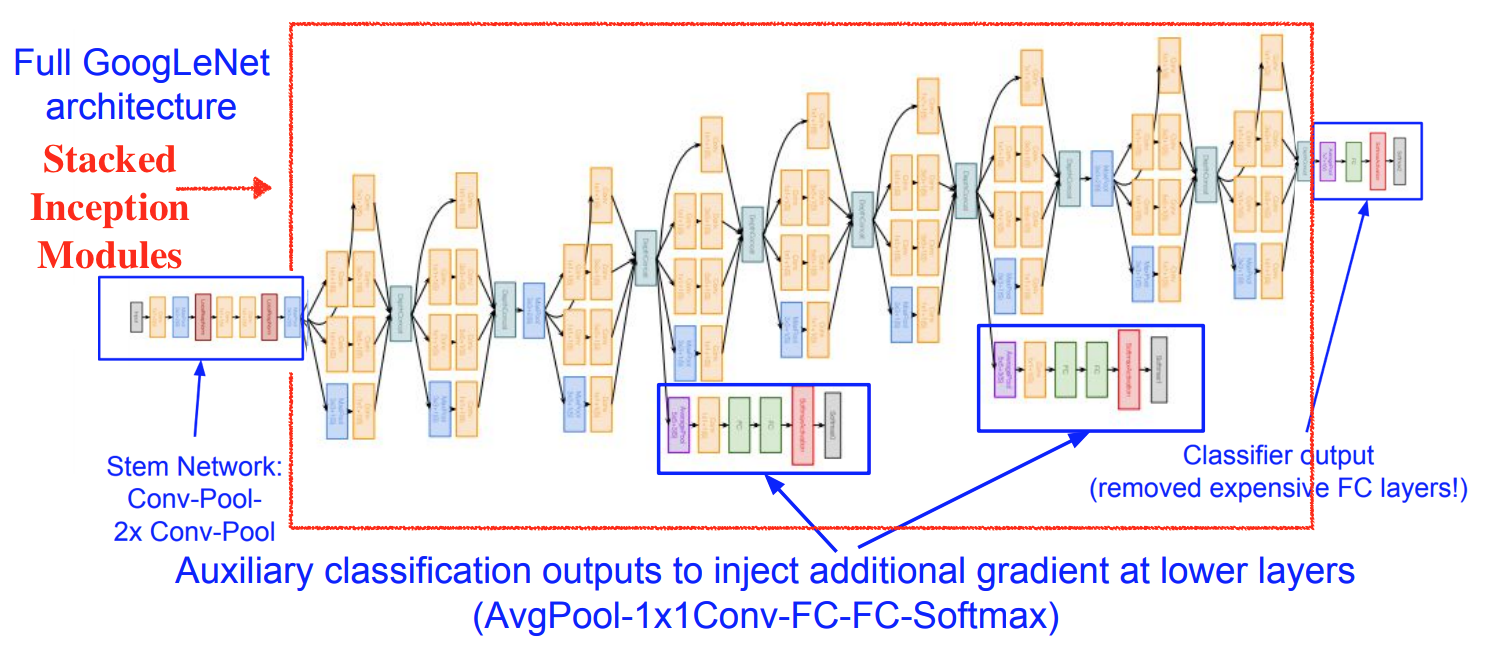
-
- Parameters:
- Parameters as specified in the Architecture and the Inception Modules
-
- Key Insights:
-
- (Even) Deeper Networks
- Computationally Efficient
- 22 layers
- Efficient “Inception” module
- No FC layers
- Only 5 million parameters: 12x less than AlexNet
-
- Inception Module:
-
- Idea: design a good local network topology (network within a network) and then stack these modules on top of each other
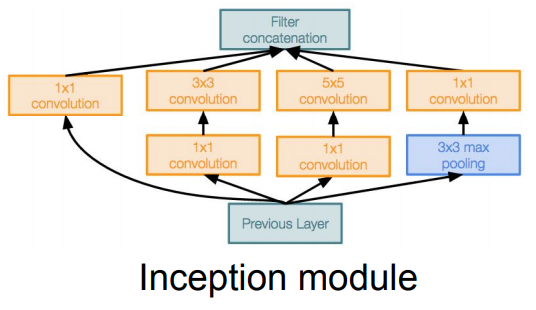
-
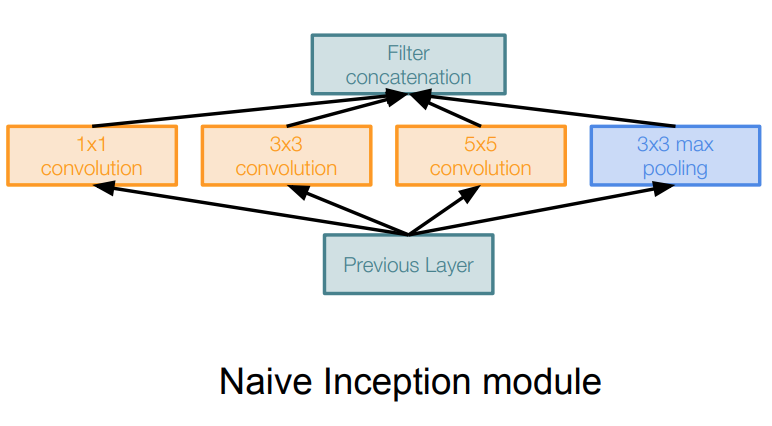
- Architecture:
- Apply parallel filter operations on the input from previous layer:
- Multiple receptive field sizes for convolution (1x1, 3x3, 5x5)
- Pooling operation (3x3)
- Concatenate all filter outputs together depth-wise
- Apply parallel filter operations on the input from previous layer:
- Architecture:
-
- Issue: Computational Complexity is very high
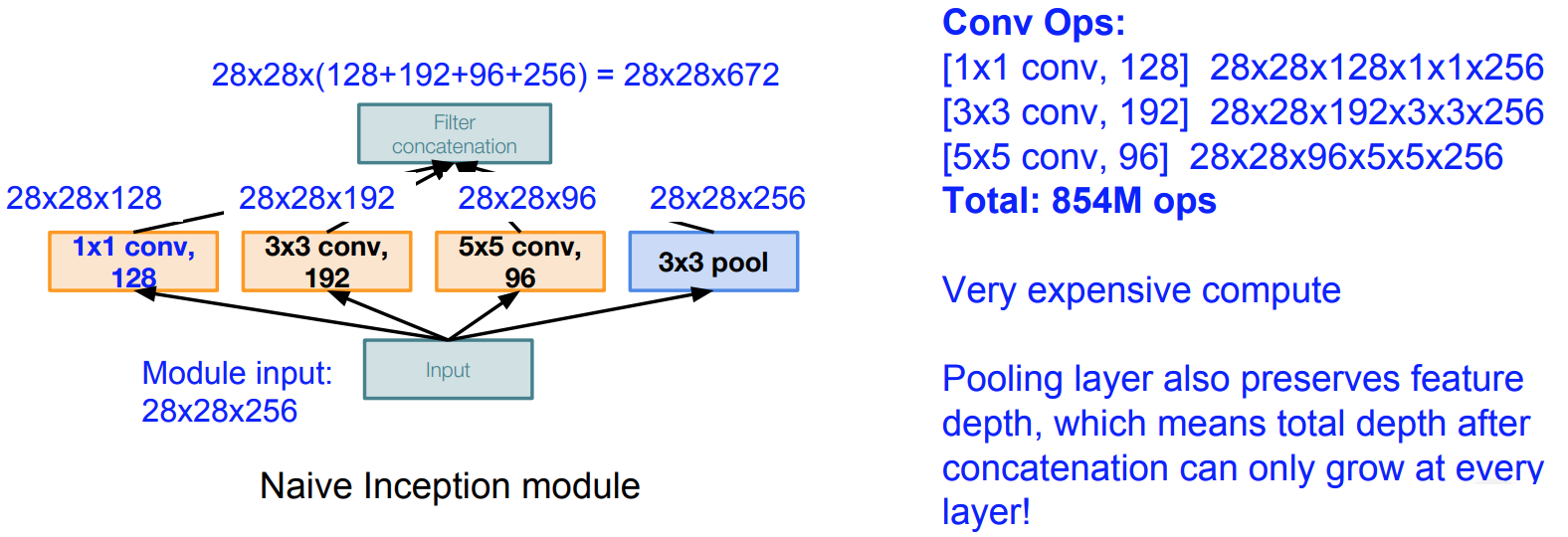
- Solution: use BottleNeck Layers that use 1x1 convolutions to reduce feature depth
preserves spatial dimensions, reduces depth!
- Issue: Computational Complexity is very high
-
- Results:
- ILSVRC’14 classification winner
ResNet (He et al., 2015)
-
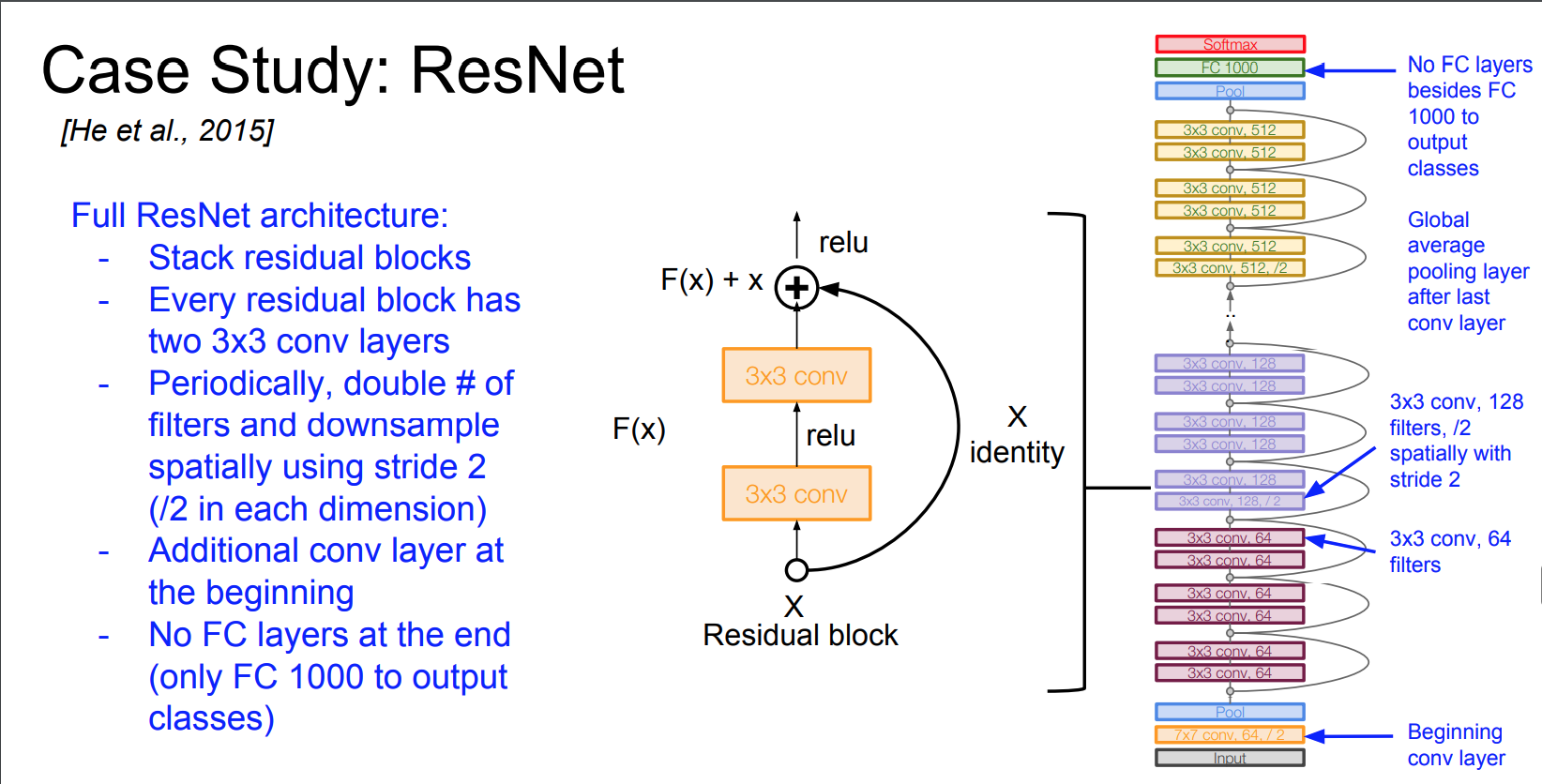
- Architecture:
-
- Key Insights:
-
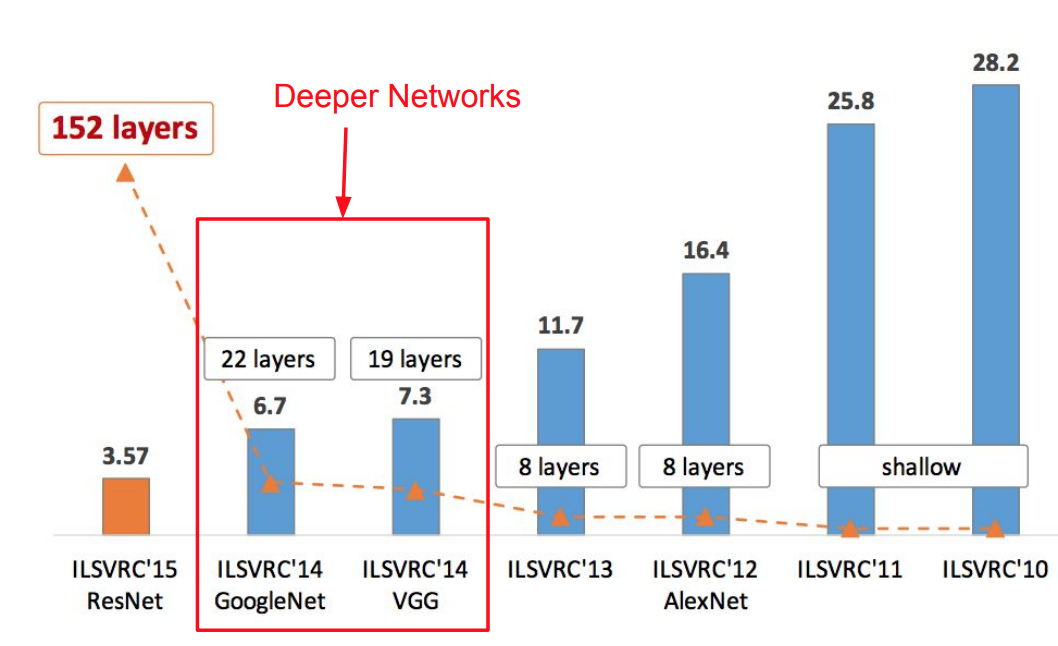
- Very Deep Network: 152-layers
- Uses Residual Connections
- Deep Networks have very bad performance NOT because of overfitting but because of a lack of adequate optimization
-
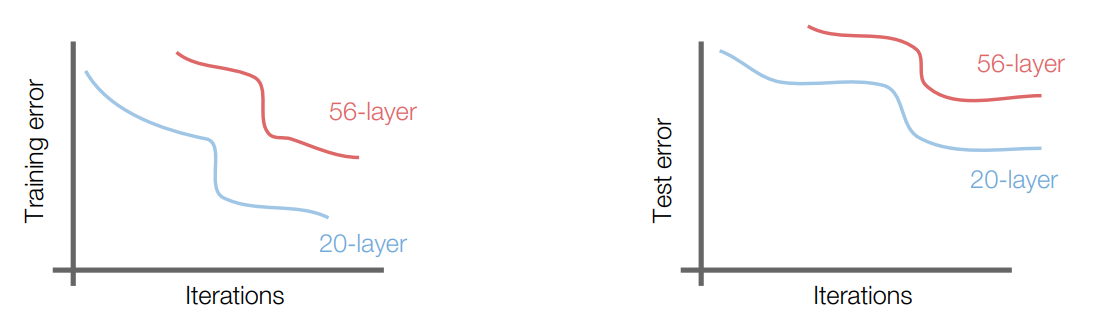
- Motivation:
-
- Observation: Deeper Networks perform badly on the test error but also on the training error
- Assumption: Deep Layers should be able to perform at least as well as the shallower models
- Hypothesis: the problem is an optimization problem, deeper models are harder to optimize
- Solution (work-around): Use network layers to fit a residual mapping instead of directly trying to fit a desired underlying mapping
-
- Residuals:
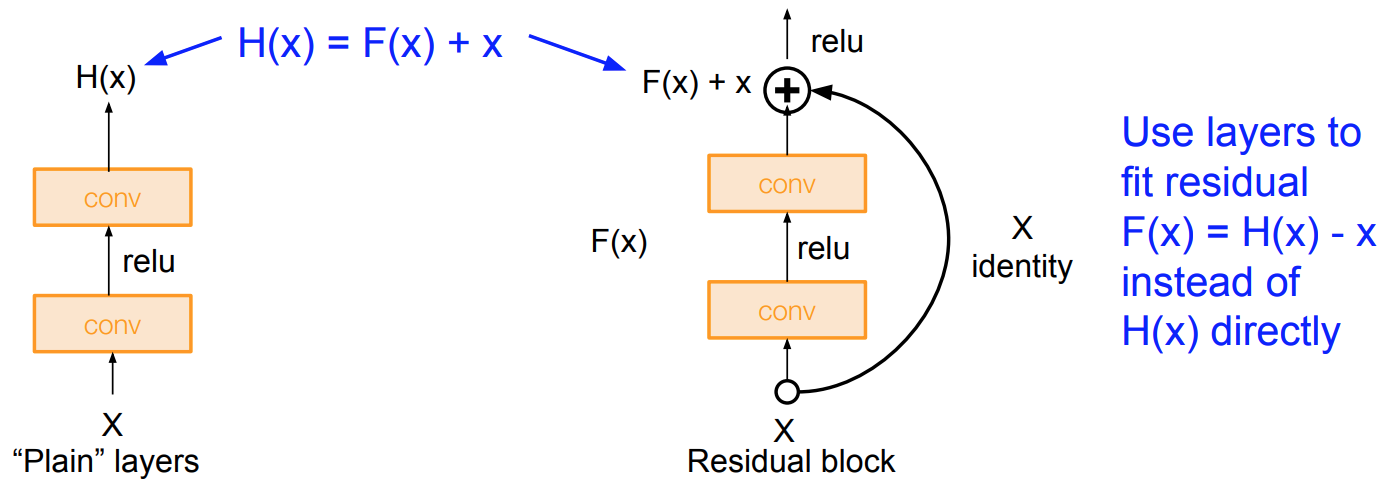
-
- BottleNecks:

-
- Training:
-
- Batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
- Batch Normalization after every CONV layer
-
- Results:
-
- ILSVRC’15 classification winner (3.57% top 5 error)
- Swept all classification and detection competitions in ILSVRC’15 and COCO’15
- Able to train very deep networks without degrading (152 layers on ImageNet, 1202 on Cifar)
- Deeper networks now achieve lowing training error as expected
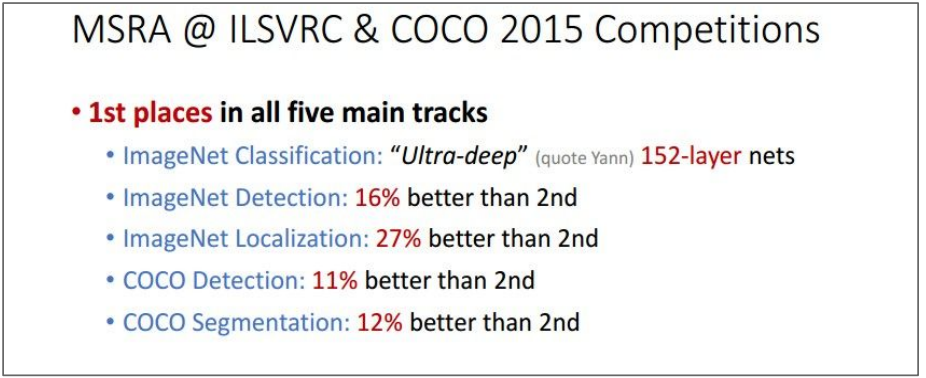
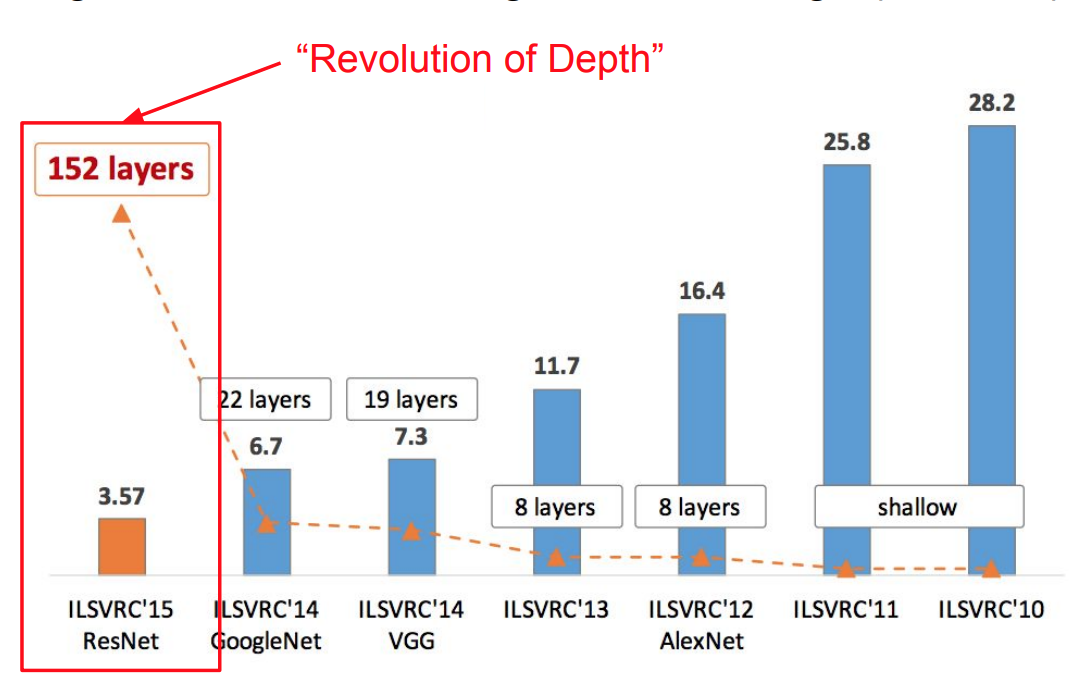
Comparisons
-
- Complexity:
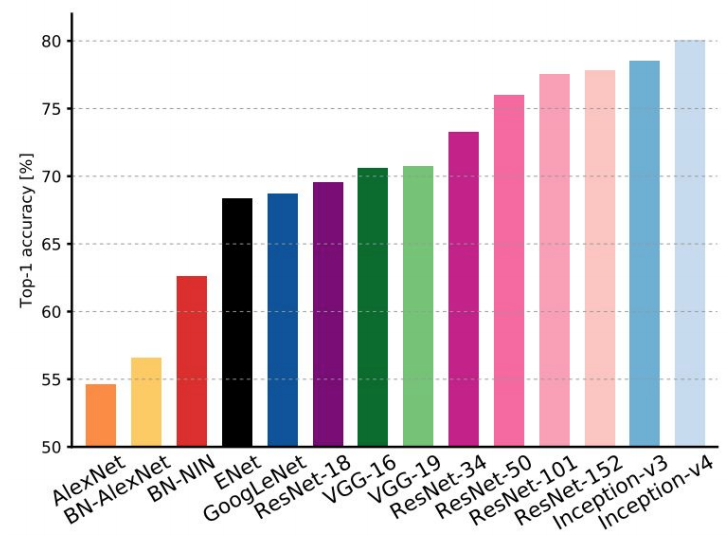
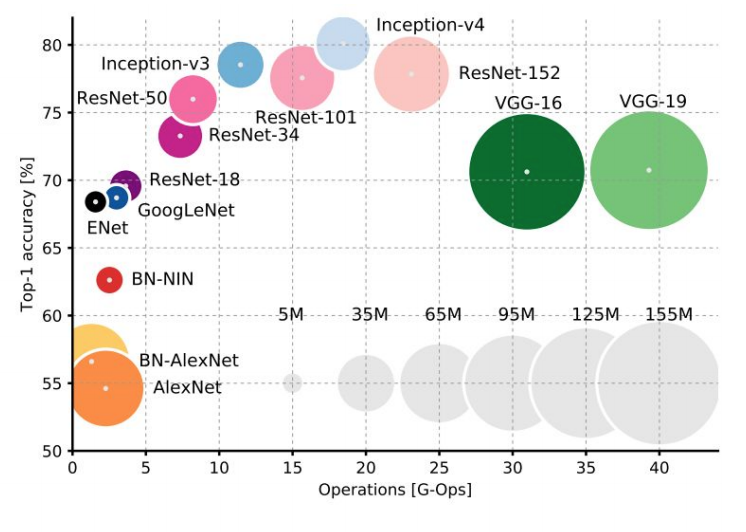
-
- Forward-Pass Time and Power Consumption:
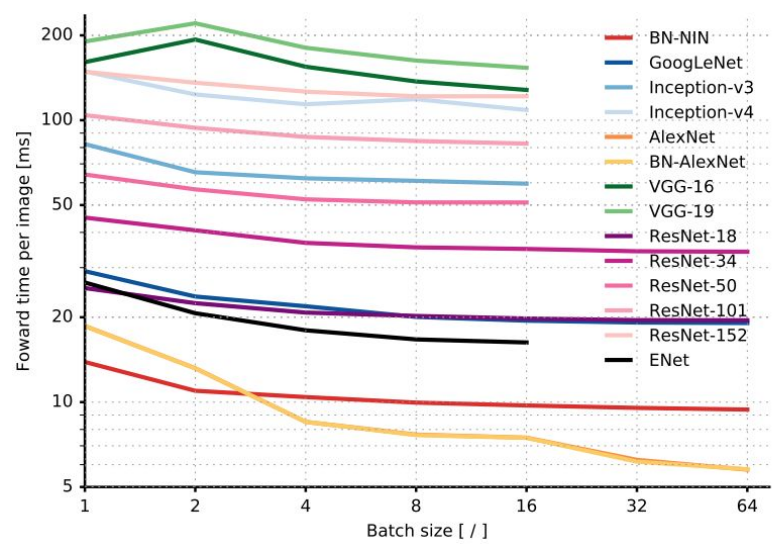
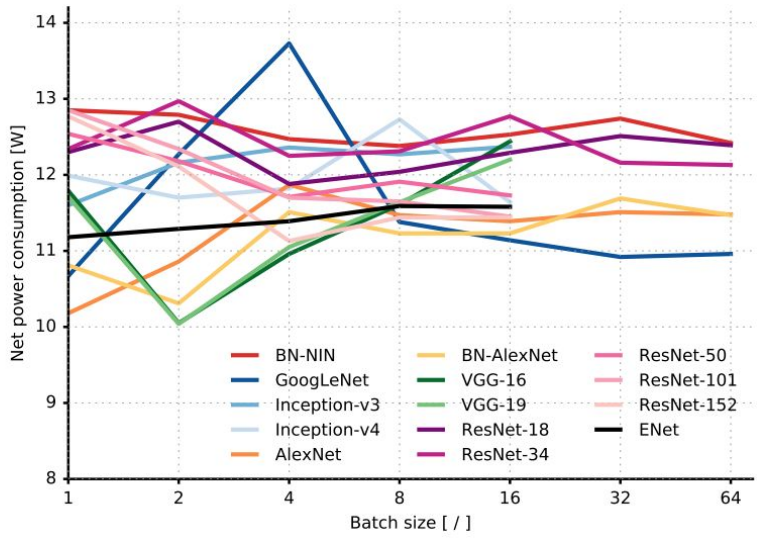
Interesting Architectures
-
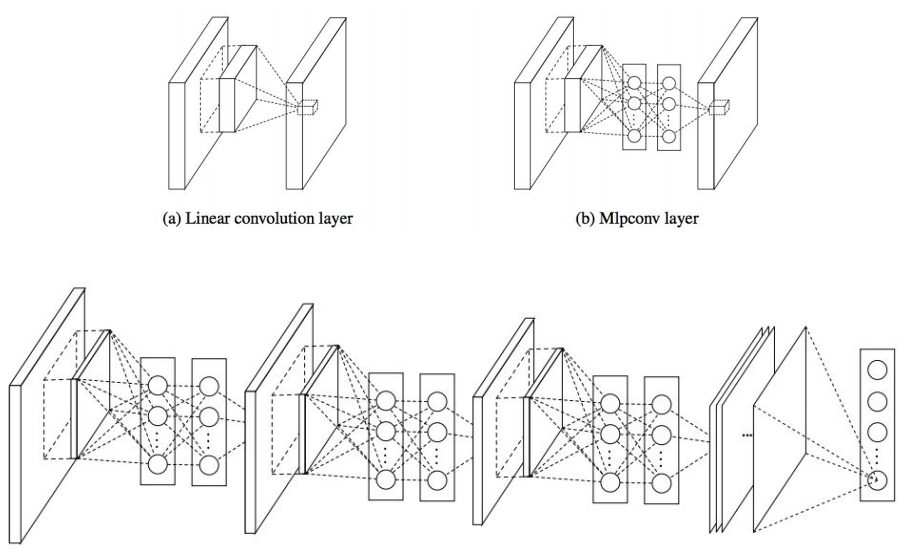
- Network in Network (NiN) [Lin et al. 2014]:
-
- Mlpconv layer with “micronetwork” within each conv layer to compute more abstract features for local patches
- Micronetwork uses multilayer perceptron (FC, i.e. 1x1 conv layers)
- Precursor to GoogLeNet and ResNet “bottleneck” layers
- Philosophical inspiration for GoogLeNet
-
- Identity Mappings in Deep Residual Networks (Improved ResNets) [He et al. 2016]:
-
- Improved ResNet block design from creators of ResNet
- Creates a more direct path for propagating information throughout network (moves activation to residual mapping pathway)
- Gives better performance
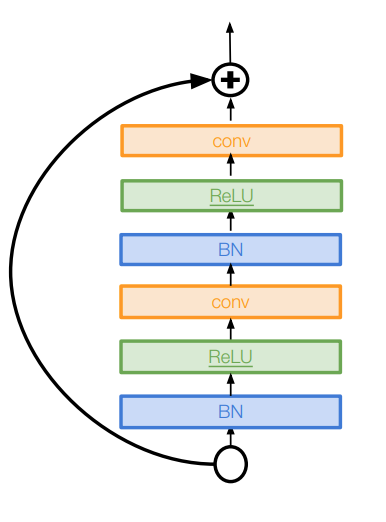
-
- Wide Residual Networks (Improved ResNets) [Zagoruyko et al. 2016]:
-
- Argues that residuals are the important factor, not depth
- User wider residual blocks (F x k filters instead of F filters in each layer)
- 50-layer wide ResNet outperforms 152-layer original ResNet
- Increasing width instead of depth more computationally efficient (parallelizable)
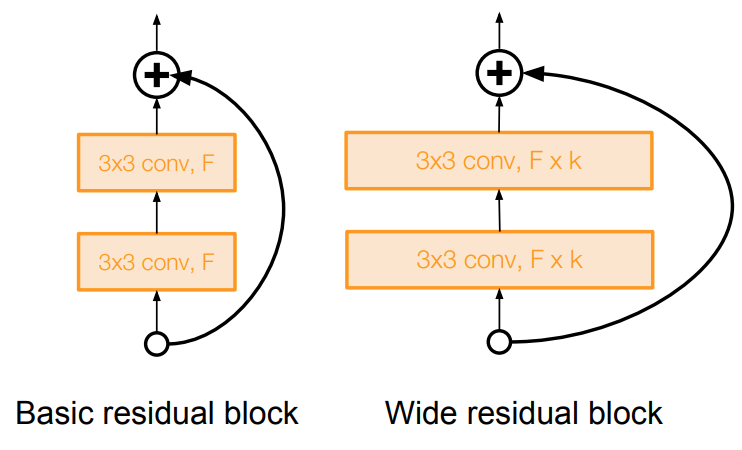
-
- Aggregated Residual Transformations for Deep Neural Networks (ResNeXt) [Xie et al. 2016]:
-
- Also from creators of ResNet
- Increases width of residual block through multiple parallel pathways (“cardinality”)
- Parallel pathways similar in spirit to Inception module
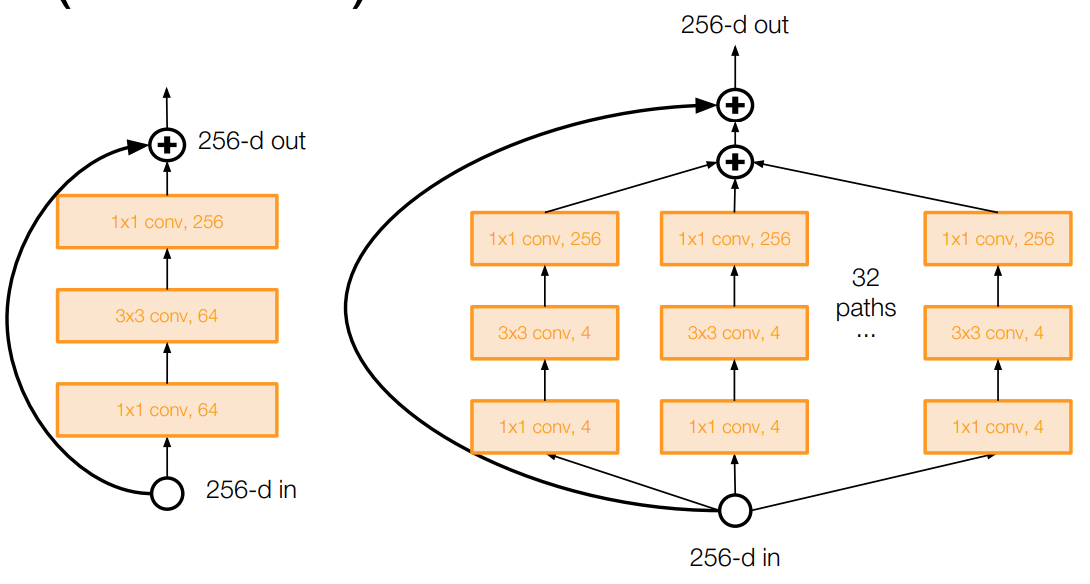
-
- Deep Networks with Stochastic Depth (Improved ResNets) [Huang et al. 2016]:
-
- Motivation: reduce vanishing gradients and training time through short networks during training
- Randomly drop a subset of layers during each training pass
- Bypass with identity function
- Use full deep network at test time
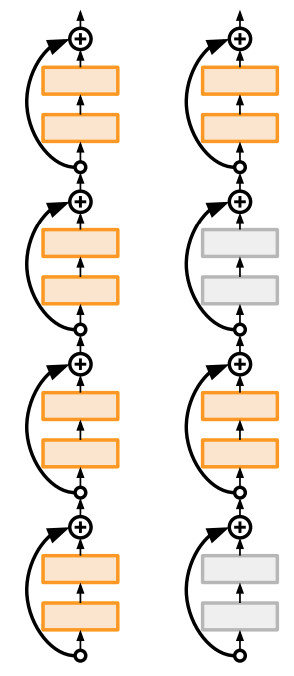
Beyond ResNets
-
- FractalNet: Ultra-Deep Neural Networks without Residuals [Larsson et al. 2017]:
-
- Argues that key is transitioning effectively from shallow to deep and residual representations are not necessary
- Fractal architecture with both shallow and deep paths to output
- Trained with dropping out sub-paths
- Full network at test time
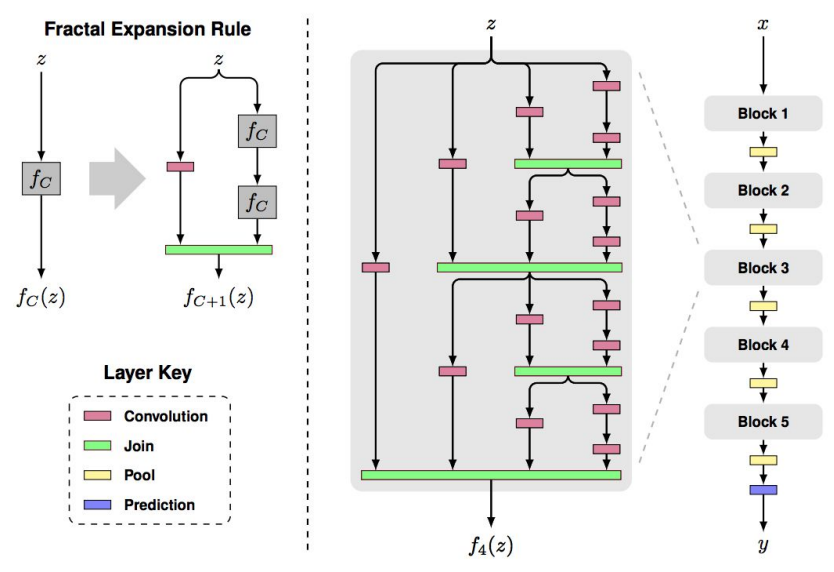
-
- Densely Connected Convolutional Networks [Huang et al. 2017]:
-
- Dense blocks where each layer is connected to every other layer in feedforward fashion
- Alleviates vanishing gradient, strengthens feature propagation, encourages feature reuse
;
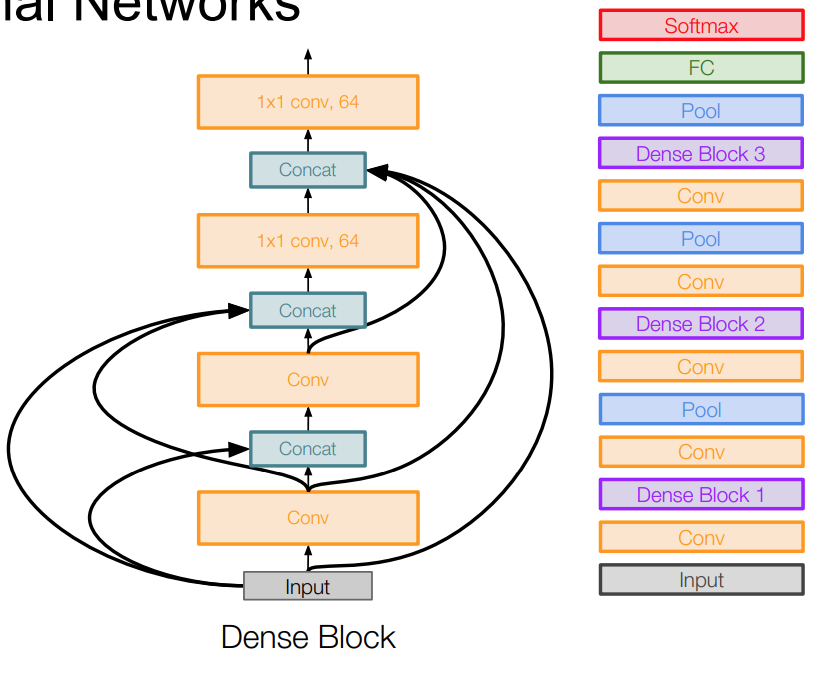
-
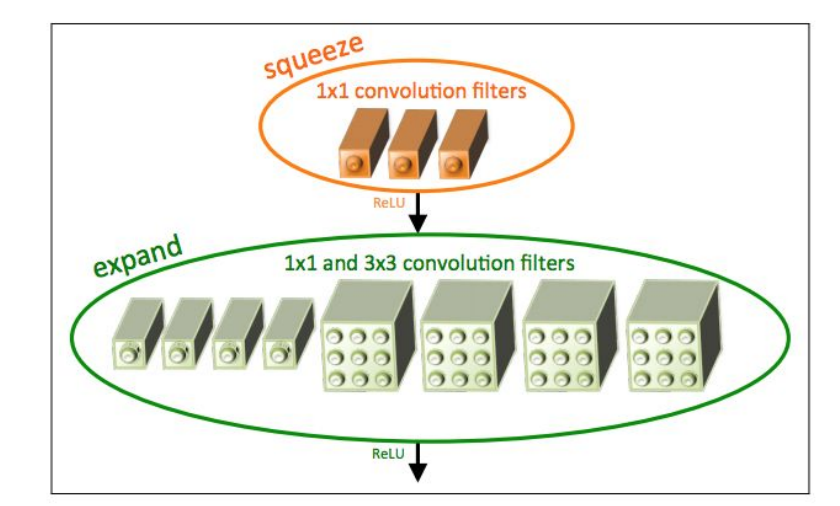
- SqueezeNet (Efficient NetWork) [Iandola et al. 2017]:
-
- AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size
- Fire modules consisting of a ‘squeeze’ layer with 1x1 filters feeding an ‘expand’ layer with 1x1 and 3x3 filters
- Can compress to 510x smaller than AlexNet (0.5Mb)