FIRST
-
Motivation:
Combination (consecutively) of words are hard to capture/model/detect. -
Padding:
Padding:- After convolution, the rows and columns of the output tensor are either:
- Equal to rows/columns of input tensor (“same” convolution)
Keeps the output dimensionality intact.
- Equal to rows/columns of input tensor minus the size of the filter plus one (“valid” or “narrow’)
- Equal to rows/columns of input tensor plus filter minus one (“wide”)
Striding:
Skip some of the outputs to reduce length of extracted feature vector
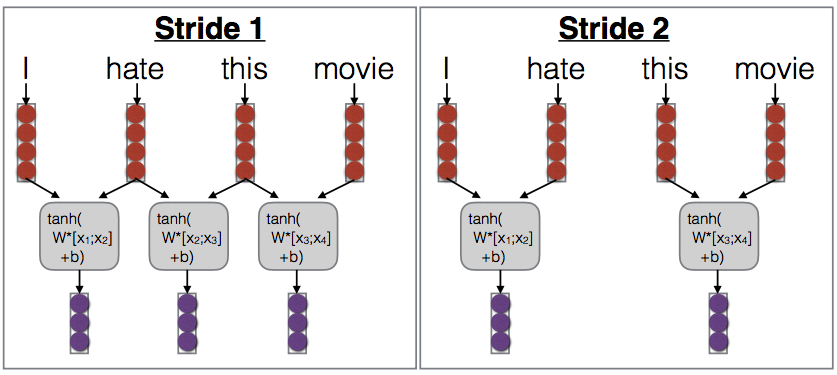 \
\
Pooling:
Pooling is like convolution, but calculates some reduction function feature-wise.
- Types:
- Max Pooling: “Did you see the feature anywhere in the range?”
- Average pooling: “How prevalent is this feature over the entire range?”
- k-Max pooling: “Did you see this feature up to k times?”
- Dynamic pooling: “Did you see this feature in the beginning? In the middle? In the end?”
Stacking - Stacked Convolution:
- Feeding in convolution from previous layer results in larger are of focus for each feature
- The increase in the number of words that are covered by stacked convolution (e.g. n-grams) is exponential in the number of layers
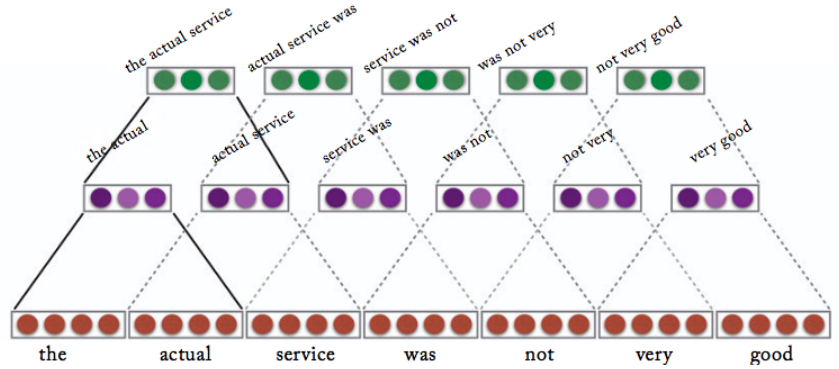 \
\
Dilation - Dilated Convolution:
Gradually increase stride, every time step (no reduction in length).
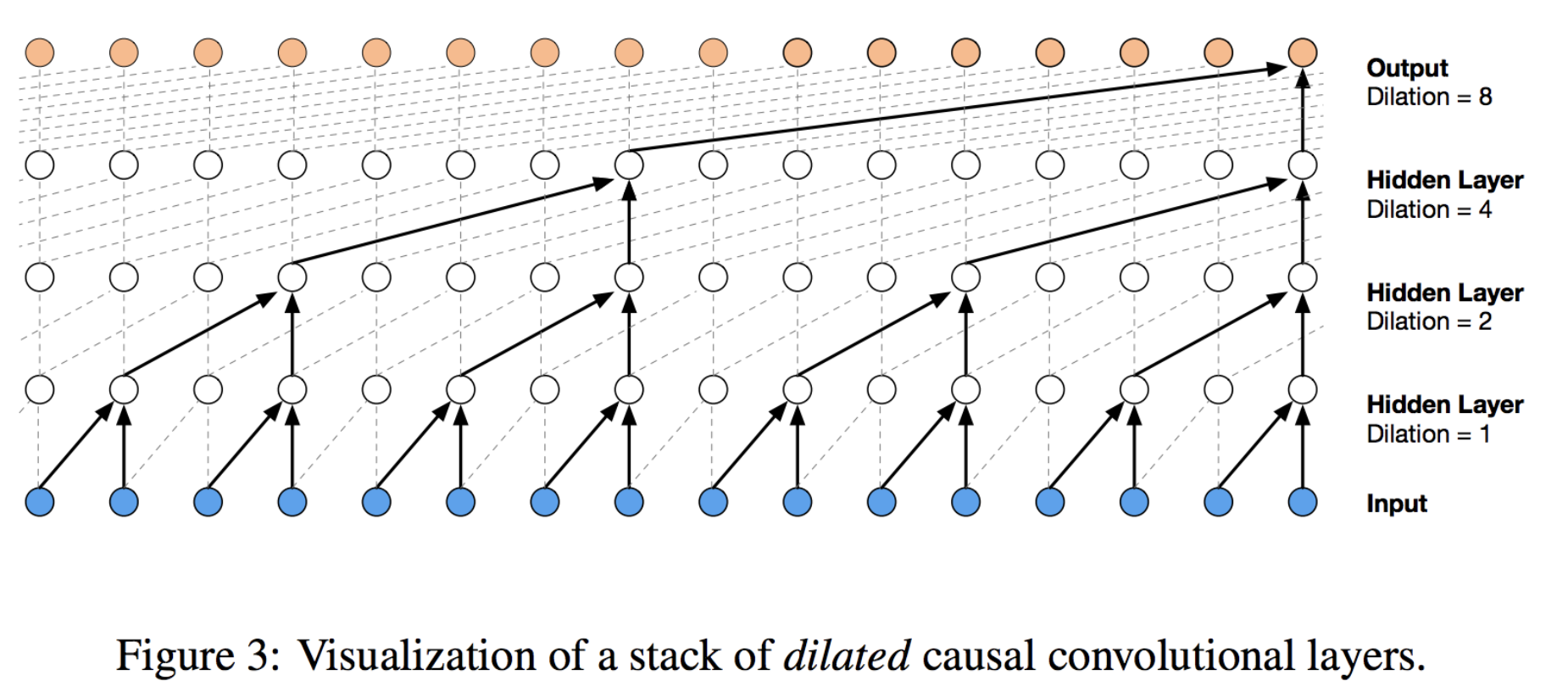
One can use the final output vector, for next target output prediction. Very useful if the problem we are modeling requires a fixed size output (e.g. auto-regressive models).
- Why (Dilated) Convolution for Modeling Sentences?
- In contrast to recurrent neural networks:
-
- Fewer steps from each word to the final representation: RNN \(O(N)\), Dilated CNN \(0(\log{N})\)
-
- Easier to parallelize on GPU
-
- Slightly less natural for arbitrary-length dependencies
-
- A bit slower on CPU?
-
- In contrast to recurrent neural networks:
- Interesting Work:
“Iterated Dilated Convolution [Strubell 2017]”:- A method for sequence labeling:
Multiple Iterations of the same stack of dilated convolutions (with different widths) to calculate context - Results:
- Wider context
- Shared parameters (i.e. more parameter efficient)
- A method for sequence labeling:
Structured Convolution:
- Why?
Language has structure, would like it to localize features.e.g. noun-verb pairs very informative, but not captured by normal CNNs
- Examples:
- Tree-Structured Convolution [Ma et al. 2015]
- Graph Convolution [Marcheggiani et al. 2017]
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
SECOND
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
THIRD
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous:
-
Asynchronous: