- Paper on Contextual Word Representations
- The Transformer Family (Blog)
- Transformer models: an introduction and catalog - 2023 Edition (Best Survey of Transformers Progress)
- Blueprints for recommender system architectures: 10th anniversary edition - AI, software, tech, and people, not in that order… by X (Blog!!!)
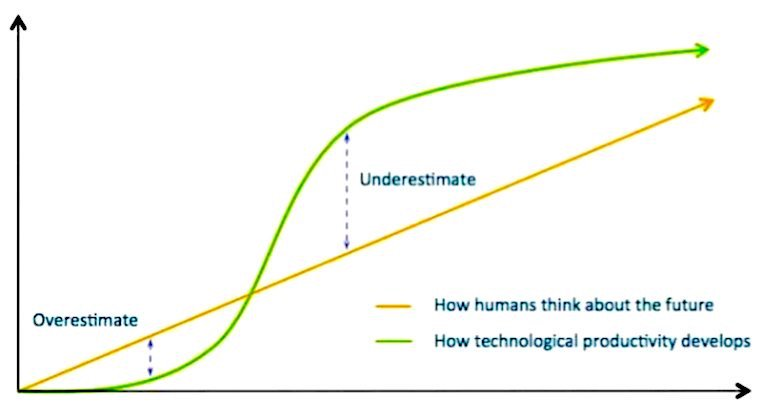
| “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.” - Amara’s law |
Word Representations and their progress
Summary of Progress:
- 2011-13s: Learning Unsupervised Representations for words (Pre-Trained Word Vectors) is crucial for making Supervised Learning work (e.g. for NERs, POS-Tagging, etc.)
- 2014-18s: Pre-Trained Word Vectors are not actually necessary for good performance of supervised methods.
- The reason is due to advances in training supervised methods: regularization, non-linearities, etc.
- They can boost the performance by ~ \(1\%\) on average.
- Word Representations (Accepted Methods):
The current accepted methods provide one representation of words:- Word2Vec
- GloVe
- FastText

Problems:
- Word Senses: Always the same representation for a word type regardless of the context in which a word token occurs
- We might want very fine-grained word sense disambiguation (e.g. not just ‘holywood star’ and ‘astronomical star’; but also ‘rock star’, ‘star student’ etc.)
- We just have one representation for a word, but words have different aspects: including semantics, syntactic behavior, and register/connotations (e.g. when is it appropriate to use ‘bathroom’ vs ‘shithole’ etc.; ‘can’-noun vs ‘can’-verb have same vector)
Possible Solution (that we always had?):
- In a NLM, LSTM layers are trained to predict the next word, producing hidden/state vectors, that are basically context-specific word representations, at each position

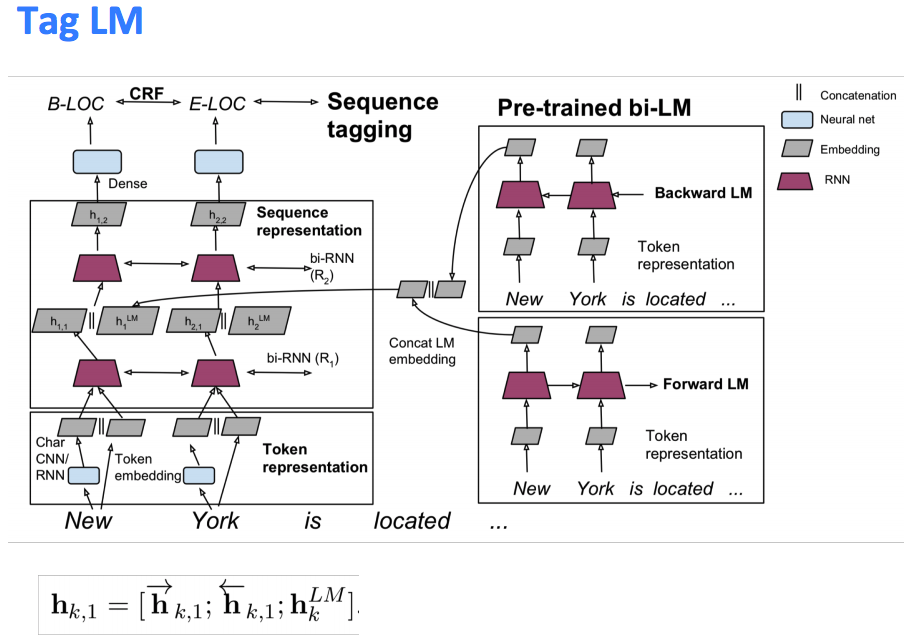
- TagLM (Peters et al. 2017) — Pre-Elmo:
Idea:- Want meaning of word in context, but standardly learn task RNN only on small task-labeled data (e.g. NER).
- Do semi-supervised approach where we train NLM on large unlabeled corpus, rather than just word vectors.
- Run a BiRNN-LM and concatenate the For and Back representations
- Also, train a traditional word-embedding (w2v) on the word and concatenate with Bi-LM repr.
- Also, train a Char-CNN/RNN to get character level embedding and concatenate all of them together
Details:
- Language model is trained on 800 million training words of “Billion word benchmark”
- Language model observations:
- An LM trained on supervised data does not help
- Having a bidirectional LM helps over only forward, by about 0.2
- Having a huge LM design (ppl 30) helps over a smaller model (ppl 48) by about 0.3
- Task-specific BiLSTM observations:
- Using just the LM embeddings to predict isn’t great: 88.17 F1
- Well below just using an BiLSTM tagger on labeled data
- Using just the LM embeddings to predict isn’t great: 88.17 F1

- Cove - Pre-Elmo:
- Also has idea of using a trained sequence model to provide context to other NLP models
- Idea: Machine translation is meant to preserve meaning, so maybe that’s a good objective?
- Use a 2-layer bi-LSTM that is the encoder of seq2seq + attention NMT system as the context provider
- The resulting CoVe vectors do outperform GloVe vectors on various tasks
- But, the results aren’t as strong as the simpler NLM training described in the rest of these slides so seems abandoned
- Maybe NMT is just harder than language modeling?
- Maybe someday this idea will return?
- Elmo - Embeddings from Language Models (Peters et al. 2018):
Idea:- Train a bidirectional LM
- Aim at performant but not overly large LM:
- Use 2 biLSTM layers
- Use character CNN to build initial word representation (only)
- 2048 char n-gram filters and 2 highway layers, 512 dim projection
- Use 4096 dim hidden/cell LSTM states with 512 dim projections to next input
- Use a residual connection
- Tie parameters of token input and output (softmax) and tie these between forward and backward LMs
Key Results:
- ELMo learns task-specific combination of BiLM representations
- This is an innovation that improves on just using top layer of LSTM stack
$$\begin{aligned} R_{k} &=\left\{\mathbf{x}_{k}^{L M}, \overrightarrow{\mathbf{h}}_{k, j}^{L M}, \mathbf{h}_{k, j}^{L M} | j=1, \ldots, L\right\} \\ &=\left\{\mathbf{h}_{k, j}^{L M} | j=0, \ldots, L\right\} \end{aligned}$$
$$\mathbf{E} \mathbf{L} \mathbf{M} \mathbf{o}_{k}^{t a s k}=E\left(R_{k} ; \Theta^{t a s k}\right)=\gamma^{task} \sum_{j=0}^{L} s_{j}^{task} \mathbf{h}_ {k, j}^{L M}$$
- \(\gamma^{\text { task }}\) scales overall usefulness of ELMo to task;
- \(s^{\text { task }}\) are softmax-normalized mixture model weights
Possibly this is a way of saying different semantic and syntactic meanings of a word are represented in different layers; and by doing a weighted average of those, in a task-specific manner, we can leverage the appropriate kind of information for each task.
Using ELMo with a Task:
- First run biLM to get representations for each word
- Then let (whatever) end-task model use them
- Freeze weights of ELMo for purposes of supervised model
- Concatenate ELMo weights into task-specific model
- Details depend on task
- Concatenating into intermediate layer as for TagLM is typical
- Can provide ELMo representations again when producing outputs, as in a question answering system
- Details depend on task
Weighting of Layers:
- The two Bi-LSTM NLP Layers have differentiated uses/meanings
- Lower layer is better for lower-level syntax, etc.
- POS-Tagging, Syntactic Dependencies, NER
- Higher layer is better for higher-level semantics
- Sentiment, Semantic role labeling, QA, SNLI
- Lower layer is better for lower-level syntax, etc.
Reason for Excitement:
ELMo proved to be great for all NLP tasks (even tho the core of the idea was in TagLM) -
ULMfit - Universal Language Model Fine-Tuning (Howard and Ruder 2018):
ULMfit - Universal Language Model Fine-Tuning for Text Classification:

-
BERT (Devlin et al. 2018):
BERT - Bidirectional Encoder Representations from Transformers:
Idea: Pre-training of Deep Bidirectional Transformers for Language Understanding.Model Architecture:
- Transformer Encoder
- Self-attention –> no locality bias
- Long-distance context has “equal opportunity”
- Single multiplication per layer –> efficiency on GPU/TPU
- Architectures:
- BERT-Base: 12 layer, 768-hidden, 12-head
- BERT-Large: 24 layer, 1024 hudden, 16 heads
Model Training:
- Train on Wikipedia + BookCorpus
- Train 2 model sizes:
- BERT-Base
- BERT-Large
- Trained on \(4\times 4\) or \(8\times 8\) TPU slice for 4 days
Model Fine-Tuning:
- Simply learn a classifier built on top layer for each task that you fine-tune for.
Problem with Unidirectional and Bidirectional LMs:
- Uni: build representation incrementally; not enough context from the sentence
- Bi: Cross-Talk; words can “see themselves”
Solution:
- Mask out \(k\%\) of the input words, and then predict the masked words
- They always use \(k=15%\)
Ex: “The man went to the [MASK] to buy a [MASK] of milk.”
- Too little Masking: Too Expensive to train
- Too much Masking: Not enough context
- They always use \(k=15%\)
- Other Benefits:
- In ELMo, bidirectional training is done independently for each direction and then concatenated. No joint-context in the model during the building of contextual-reprs.
- In GPT, there is only unidirectional context.
Another Objective - Next Sentence Prediction:
To learn relationships between sentences, predict whether sentence B is actual sentence that proceeeds sentence A, or a random sentence (for QA, NLU, etc.).Results:
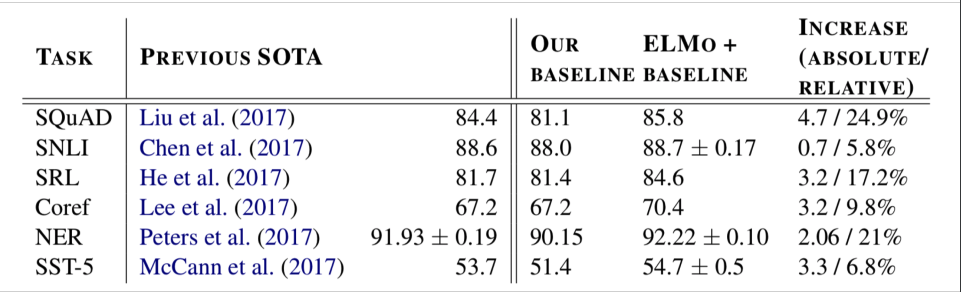
Beats every other architecture in every GLUE task (NL-Inference).
Notes:
- Tips for unknown words with word vectors:
- Simplest and common solution:
- Train time: Vocab is \(\{\text { words occurring, say, } \geq 5 \text { times }\} \cup\{<UNK>\}\)
- Map all rarer \((<5)\) words to \(<UNK>\), train a word vector for it
-
Runtime: use \(<UNK>\) when out-of-vocabulary (OOV) words occur
- Problems:
- No way to distinguish different \(UNK\) words, either for identity or meaning
- Solutions:
- Hey, we just learned about char-level models to build vectors! Let’s do that!
- Especially in applications like question answering
- Where it is important to match on word identity, even for words outside your word vector vocabulary
- Especially in applications like question answering
-
Try these tips (from Dhingra, Liu, Salakhutdinov, Cohen 2017)
a. If theword at test time appears in your unsupervised word embeddings, use that vector as is at test time. b. Additionally, for other words, just assign them a random vector, adding them to your vocabulary a. definitely helps a lot; b. may help a little more
- Another thing you can try:
- Collapsing things to word classes (like unknown number, capitalized thing, etc. and having an
for each
- Collapsing things to word classes (like unknown number, capitalized thing, etc. and having an
- Hey, we just learned about char-level models to build vectors! Let’s do that!
The Transformer
-
Self-Attention:
Computational Complexity Comparison:

It is favorable when the sequence-length \(<<\) dimension-representations.Self-Attention/Relative-Attention Interpretations:
- Can achieve Translational Equivariance (like convs) (by removing pos-encoding).
- Can model similarity graphs.
- Connected to message-passing NNs: Can think of self-attention as passing messages between pairs of nodes in graph; equivalently, imposing a complete bipartite graph and you’re passing messages between nodes.
Mathematically, the difference is message-passing NNs impose condition that messages pass ONLY bet pairs of nodes; while self-attention uses softmax and thus passes messages between all nodes.
Self-Attention Summary/Properties:
- Constant path-length between any two positions
- Unbounded memory (i.e no fixed size h-state)
- Gating/multiplicative interactions
Because you multiply attention probabilities w/ activations. PixelCNN needed those interactions too. - Trivial to parallelize (per layer): just matmuls
- Models self-similarity
- Relative attention provides expressive timing, equivariance, and extends naturally to graphs
- (Without positional encoding) It’s Permutation-Invariant and Translation-Equivariant
It can learn to copy well.
Current Issues:
- Slow Generation:
Mainly due to Auto-Regressive generation, which is necessary to break the multi-modality of generation. Multi-modality prohibits naive parallel generation.
Multi-modality refers to the fact that there are multiple different sentences in german that are considered a correct translation of a sentence in english, and they all depend on the word that was generated first (ie no parallelization). - Active Area of Research:
Non Auto-Regressive Transformers.- Papers:
- Non autoregressive transformer (Gu and Bradbury et al., 2018)
- Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement (Lee, Manismov, and Cho, 2018)
- Fast Decoding in Sequence Models Using Discrete Latent Variables (ICML 2018) Kaiser, Roy, Vaswani, Pamar, Bengio, Uszkoreit, Shazeer
- Towards a Better Understanding of Vector Quantized Autoencoders Roy, Vaswani, Parmar, Neelakantan, 2018
- Blockwise Parallel Decoding For Deep Autogressive Models (NeurIPS 2019) Stern, Shazeer, Uszkoreit
- Papers:
Notes:
- Self-Similarity:
- Use Encoder-Self-Attention and replace word-embeddings with image-patches: you compute a notion of content-based similarity between the elements (patches), then - based on this content-based similarity - it computes a convex combination that brings the patches together.
- You can think about it as a differentiable way to perform non-local means.
- Issue - Computational Problem:
Attention is Cheap only if length \(<<\) dim.
Length for images is \(32\times 32\times 3 = 3072\):

- Solution - Combining Locality with Self-Attention:
Restrict the attention windows to be local neighborhoods.
Good assumption for images because of spatial locality.
- Use Encoder-Self-Attention and replace word-embeddings with image-patches: you compute a notion of content-based similarity between the elements (patches), then - based on this content-based similarity - it computes a convex combination that brings the patches together.