Table of Contents
Deep Speech
-
- Introduction:
- This paper takes a first attempt at an End-to-End system for ASR.
-
- Structure:
-
- Input: vector of speech spectrograms
- An utterance \(x^{(i)}\): is a time-series of length \(T^{(i)}\) composed of time-slices where each is a vector of audio (spectrogram) features \(x_{t,p}^{(i)}, t=1,...,T^{(i)}\), where \(p\) denotes the power of the p’th frequency bin in the audio frame at time \(t\).
- Output: English text transcript \(y\)
- Input: vector of speech spectrograms
-
- Goal:
The goal of the RNN is to convert an input sequence \(x\) into a sequence of character probabilities for the transcription \(y\), with \(\tilde{y}_t = P(c_t\vert x)\), where \(c_t \in \{\text{a, b, c, } \ldots \text{, z, space, apostrophe, blank}\}\).
- Goal:
-
- Strategy:
- The goal is to replace the multi-part model with a single RNN network that captures as much of the information needed to do transcription in a single system.
-
- Solves:
-
- Previous models only used DNNs as a single component in a complex pipeline.
NNs are trained to classify individual frames of acoustic data, and then, their output distributions are reformulated as emission probabilities for a HMM.
In this case, the objective function used to train the networks is therefore substantially different from the true performance measure (sequence-level transcription accuracy.
This leads to problems where one system might have an improved accuracy rate but the overall transcription accuracy can still decrease. - An additional problem is that the frame-level training targets must be inferred from the alignments determined by the HMM. This leads to an awkward iterative procedure, where network retraining is alternated with HMM re-alignments to generate more accurate targets.
- Previous models only used DNNs as a single component in a complex pipeline.
-
- Key Insights:
-
- As an End-to-End model, this system avoids the problems of multi-part systems that lead to inconsistent training criteria and difficulty of integration.
The network is trained directly on the text transcripts: no phonetic representation (and hence no pronunciation dictionary or state tying) is used. - Using CTC objective, the system is able to better approximate and solve the alignment problem avoiding HMM realignment training.
Since CTC integrates out over all possible input-output alignments, no forced alignment is required to provide training targets. - The Dataset is augmented with newly synthesized data and modified to include all the variations and effects that face ASR problems.
This greatly increases the system performance on particularly noisy/affected speech.
- As an End-to-End model, this system avoids the problems of multi-part systems that lead to inconsistent training criteria and difficulty of integration.
-
- Preparing Data (Pre-Processing):
- The paper uses spectrograms of power normalized audio clips as features.
-
- Architecture:
- The system is composed of:
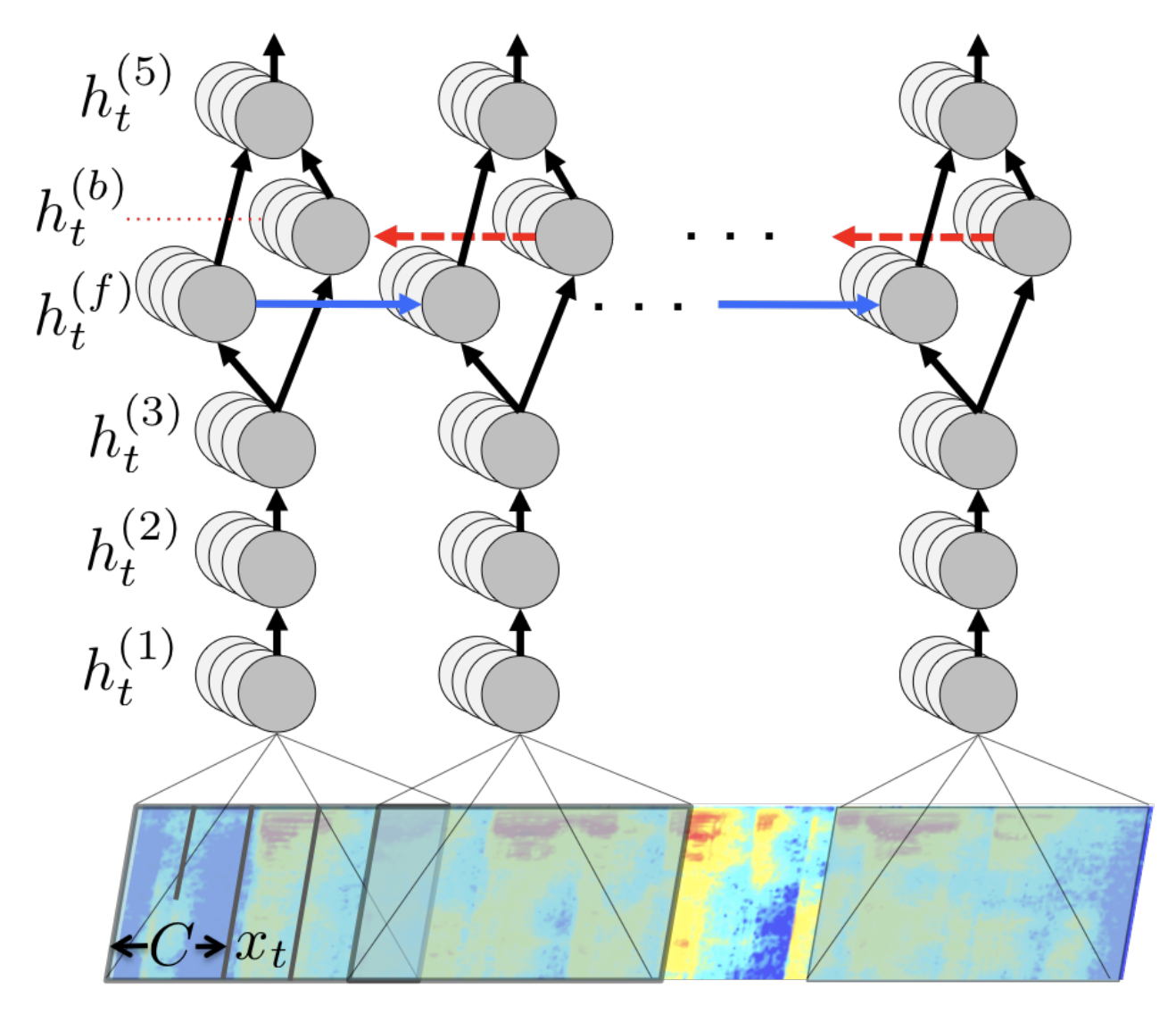
- An RNN:
- 5 layers of hidden units:
- 3 Layer of Feed-forward Nets:
- For the input layer, the output depends on the spectrogram frame \(x_t\) along with a context of \(C\) frames on each side.
\[C \in \{5, 7, 9\}\]
- The non-recurrent layers operate on independent data for each time step:
\(h_t^{(l)} = g(W^{(l)} h_{(t)}^{(l-1)} + b^{(l)}),\)
where \(g(z) = \min \{\max \{0, z\}, 20\}\) is the clipped RELU.
- For the input layer, the output depends on the spectrogram frame \(x_t\) along with a context of \(C\) frames on each side.
- 2 layers of Recurrent Nets:
- 1 layer of a Bi-LSTM:
- Includes two sets of hidden units:
A set with forward recurrence \(h^{(f)}\)
A set with backward recurrence \(h^{(b)}\):
\(h_t^{(f)} = g(W^{(4)}h_t^{(3)} + W_r^{(b)} h_{t-1}^{(b)} + b ^{(4)}) \\ h_t^{(b)} = g(W^{(4)}h_t^{(3)} + W_r^{(b)} h_{t+1}^{(b)} + b ^{(4)})\)Note that \(h^{(f)}\) must be computed sequentially from \(t = 1\) to \(t = T^{(i)}\) for the i’th utterance, while the units \(h^{(b)}\) must be computed sequentially in reverse from \(t = T^{(i)}\) to \(t = 1\).
- Includes two sets of hidden units:
A set with forward recurrence \(h^{(f)}\)
- 1 layer of Feed-forward Nets:
- The fifth (non-recurrent) layer takes both the forward and backward units as inputs:
\(h_t^{(5)} = g(W ^{(5)}h_t ^{(4)} + b ^{(5)}),\)
where \(h_t^{(4)} = h_t^{(f)} + h_t^{(b)}\)
- The fifth (non-recurrent) layer takes both the forward and backward units as inputs:
- 1 layer of a Bi-LSTM:
- 3 Layer of Feed-forward Nets:
- An Output layer made of a standard softmax function that yields the predicted character probabilities for each time-slice \(t\) and character \(k\) in the alphabet:
\(\displaystyle{h _{(t,k)} ^{(6)} = \hat{y} _{(t,k)} = P(c_t = k \vert x) = \dfrac{\exp (W_k ^{(6)} h_t ^{(5)} + b_k ^{(6)})}{\sum_j \exp (W_j ^{(6)}h_t ^{(5)} + b_j ^{(6)})}},\)
where \(W_k ^{(6)}\) and \(b_k ^{(6)}\) denote the k’th column of the weight matrix and k’th bias.
- 5 layers of hidden units:
- A CTC Loss Function \(\mathcal{L}(\hat{y}, y)\)
- An N-gram Language Model
- A combined Objective Function:
- An RNN:
- \[Q(c) = \log (P(x \vert x)) + \alpha \log (P_{\text{LM}}(c) + \beta \text{word_count}(c))\]
-
- Algorithm:
-
- Given the output \(P(c \vert x)\) of the RNN: perform a search to find the sequence of characters \(c_1, c_2, ...\) that is most probable according to both:
- The RNN Output
- The Language Model
- We maximize the combined objective:
\(Q(c) = \log (P(x \vert x)) + \alpha \log (P_{\text{LM}}(c) + \beta \text{word_count}(c))\)
where the term \(P_{\text{lm}} denotes the probability of the sequence\)c$$ according to the N-gram model. - The objective is maximized using a highly optimized beam search algorithm
beam size: 1000-8000
- Given the output \(P(c \vert x)\) of the RNN: perform a search to find the sequence of characters \(c_1, c_2, ...\) that is most probable according to both:
-
- Training:
-
- The gradient of the CTC Loss \(\nabla_{\hat{y}} \mathcal{L}(\hat{y}, y)\) with respect to the net outputs given the ground-truth character sequence \(y\) is computed
-
- Nesterov’s Accelerated gradient
- Nesterov Momentum
- Annealing the learning rate by a constant factor
- Dropout
- Striding – shortening the recurrent layers by taking strides of size \(2\).
The unrolled RNN will have half as many steps.similar to a convolutional network with a step-size of 2 in the first layer.
-
- Parameters:
-
- Momentum: \(0.99\)
- Dropout: \(5-10 \%\) (FFN only)
- Trade-Off Params: use cross-validation for \(\alpha, \beta\)
-
- Issues/The Bottleneck:
-
- Results:
-
- SwitchboardHub5’00 (
WER):
- Standard: \(16.0\%\)
- w/Lexicon of allowed words: \(21.9\%\)
- Trigram LM: \(8.2\%\)
- w/Baseline system: \(6.7\%\)
- SwitchboardHub5’00 (
WER):
-
- Discussion:
-
- Why avoid LSTMs:
One disadvantage of LSTM cells is that they require computing and storing multiple gating neuron responses at each step.
Since the forward and backward recurrences are sequential, this small additional cost can become a computational bottleneck.
- Why avoid LSTMs:
-
- Why a homogeneous model:
By using a homogeneous model we have made the computation of the recurrent activations as efficient as possible: computing the ReLu outputs involves only a few highly optimized BLAS operations on the GPU and a single point-wise nonlinearity.
- Why a homogeneous model:
-
- Further Development:
Towards End-to-End Speech Recognition with Recurrent Neural Networks
-
- Introduction:
- This paper presents an ASR system that directly transcribes audio data with text, without requiring an intermediate phonetic representation.
-
- Structure:
-
- Input:
- Output:
-
- Strategy:
- The goal of this paper is a system where as much of the speech pipeline as possible is replaced by a single recurrent neural network (RNN) architecture.
The language model, however, will be lacking due to the limitation of the audio data to learn a strong LM.
-
- Solves:
-
- First attempts used RNNs or standard LSTMs. These models lacked the complexity that was needed to capture all the models required for ASR.
-
- Key Insights:
-
- The model uses Bidirectional LSTMs to capture the nuances of the problem.
- The system uses a new objective function that trains the network to directly optimize the WER.
-
- Preparing the Data (Pre-Processing):
- The paper uses spectrograms as a minimal preprocessing scheme.
-
- Architecture:
- The system is composed of:
- A Bi-LSTM
- A CTC output layer
- A combined objective function:
The new objective function at allows an RNN to be trained to optimize the expected value of an arbitrary loss function defined over output transcriptions (such as WER).
Given input sequence \(x\), the distribution \(P(y\vert x)\) over transcriptions sequences \(y\) defined by CTC, and a real-valued transcription loss function \(\mathcal{L}(x, y)\), the expected transcription loss \(\mathcal{L}(x)\) is defined:$$\begin{align} \mathcal{L}(x) &= \sum_y P(y \vert x)\mathcal{L}(x,y) \\ &= \sum_y \sum_{a \in \mathcal{B}^{-1}(y)} P(a \vert x)\mathcal{L}(x,y) \\ &= \sum_a P(a \vert x)\mathcal{L}(x,\mathcal{B}(a)) \end{align}$$

-
- Algorithm:
-
- Issues/The Bottleneck:
-
- Results:
-
- WSJC (
WER):
- Standard: \(27.3\%\)
- w/Lexicon of allowed words: \(21.9\%\)
- Trigram LM: \(8.2\%\)
- w/Baseline system: \(6.7\%\)
- WSJC (
WER):
Attention-Based Models for Speech Recognition
-
- Introduction:
- This paper introduces and extends the attention mechanism with features needed for ASR. It adds location-awareness to the attention mechanism to add robustness against different lengths of utterances.
-
- Motivation:
- Learning to recognize speech can be viewed as learning to generate a sequence (transcription) given another sequence (speech).
From this perspective it is similar to machine translation and handwriting synthesis tasks, for which attention-based methods have been found suitable. - How ASR differs:
Compared to Machine Translation, speech recognition differs by requesting much longer input sequences which introduces a challenge of distinguishing similar speech fragments in a single utterance.thousands of frames instead of dozens of words
- It is different from Handwriting Synthesis, since the input sequence is much noisier and does not have a clear structure.
-
- Structure:
-
- Input: \(x=(x_1, \ldots, x_{L'})\) is a sequence of feature vectors
- Each feature vector is extracted from a small overlapping window of audio frames
- Output: \(y\) a sequence of phonemes
- Input: \(x=(x_1, \ldots, x_{L'})\) is a sequence of feature vectors
-
- Strategy:
- The goal of this paper is a system, that uses attention-mechanism with location awareness, whose performance is comparable to that of the conventional approaches.
-
- For each generated phoneme, an attention mechanism selects or weighs the signals produced by a trained feature extraction mechanism at potentially all of the time steps in the input sequence (speech frames).
- The weighted feature vector then helps to condition the generation of the next element of the output sequence.
- Since the utterances in this dataset are rather short (mostly under 5 seconds), we measure the ability of the considered models in recognizing much longer utterances which were created by artificially concatenating the existing utterances.
-
- Solves:
-
- Problem:
The attention-based model proposed for NMT demonstrates vulnerability to the issue of similar speech fragments with longer, concatenated utterances.
The paper argues that this model adapted to track the absolute location in the input sequence of the content it is recognizing, a strategy feasible for short utterances from the original test set but inherently unscalable. - Solution:
The attention-mechanism is modified to take into account the location of the focus from the previous step and the features of the input sequence by adding as inputs to the attention mechanism auxiliary Convolutional Features which are extracted by convolving the attention weights from the previous step with trainable filters.
- Problem:
-
- Key Insights:
-
- Introduces attention-mechanism to ASR
- The attention-mechanism is modified to take into account:
- location of the focus from the previous step
- features of the input sequence
- Proposes a generic method of adding location awareness to the attention mechanism
- Introduce a modification of the attention mechanism to avoid concentrating the attention on a single frame
-
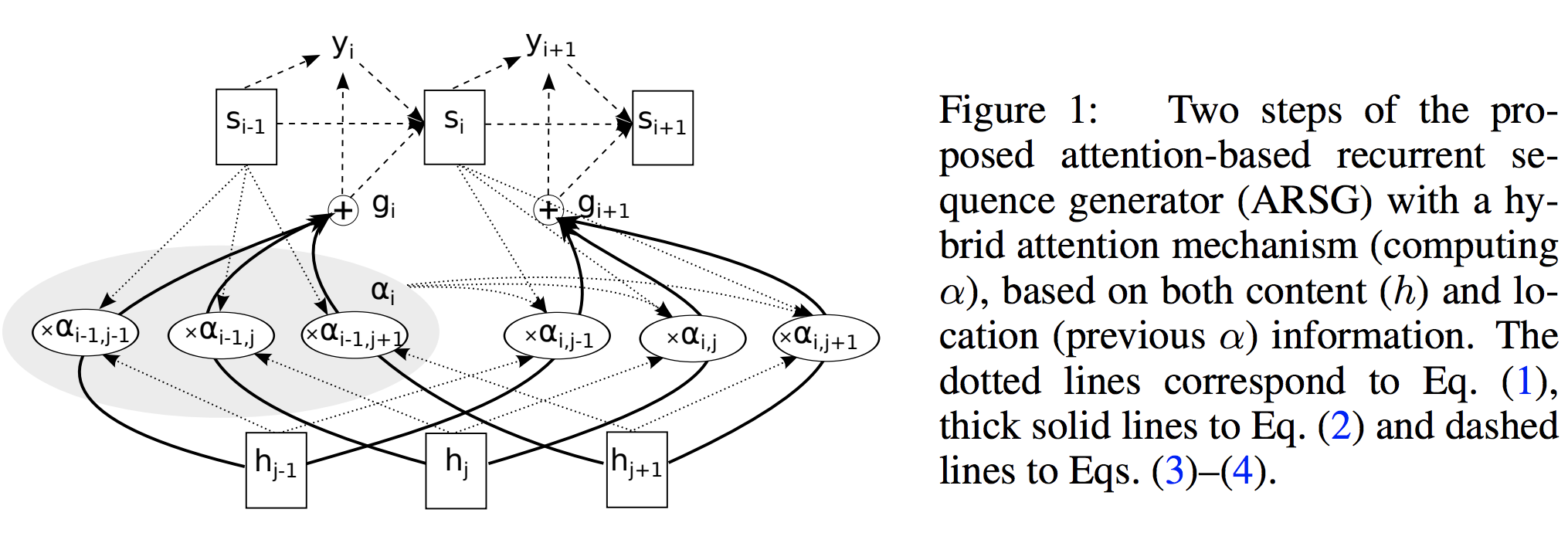
- Attention-based Recurrent Sequence Generator (ARSG):
- is a recurrent neural network that stochastically generates an output sequence \((y_1, \ldots, y_T)\) from an input \(x\).
In practice, \(x\) is often processed by an encoder which outputs a sequential input representation \(h = (h_1, \ldots, h_L)\) more suitable for the attention mechanism to work with. - The Encoder: a deep bidirectional recurrent network.
It forms a sequential representation h of length \(L = L'\). - Structure:
- Input: \(x = (x_1, \ldots, x_{L'})\) is a sequence of feature vectors
Each feature vector is extracted from a small overlapping window of audio frames.
- Output: \(y\) is a sequence of phonemes
- Input: \(x = (x_1, \ldots, x_{L'})\) is a sequence of feature vectors
- Strategy:
At the \(i\)-th step an ARSG generates an output \(y_i\) by focusing on the relevant elements of \(h\): - \[\begin{align} \alpha_i &= \text{Attend}(s_{i-1}, \alpha _{i-1}), h) & (1) \\ g_i &= \sum_{j=1}^L \alpha_{i,j} h_j & (2) // y_i &\sim \text{Generate}(s_{i-1}, g_i) & (3) \end{align}\]
- where \(s_{i−1}\) is the \((i − 1)\)-th state of the recurrent neural network to which we refer as the generator, \(\alpha_i \in \mathbb{R}^L\) is a vector of the attention weights, also often called the alignment; and \(g_i\) is the glimpse.
The step is completed by computing a new generator state: - \[s_i = \text{Recurrency}(s_{i-1}, g_i, y_i)\]
- where the Recurrency is an RNN.
-
- Attention-mechanism Types and Speech Recognition:
- Types of Attention:
- (Generic) Hybrid Attention: \(\alpha_i = \text{Attend}(s_{i-1}, \alpha_{i-1}, h)\)
- Content-based Attention: \(\alpha_i = \text{Attend}(s_{i-1}, h)\)
In this case, Attend is often implemented by scoring each element in h separately and normalizing the scores:
\(e_{i,j} = \text{Score}(s_{i-1}, h_j) \\\) \(\alpha_{i,j} = \dfrac{\text{exp} (e_{i,j}) }{\sum_{j=1}^L \text{exp}(e_{i,j})}\)- Limitations:
The main limitation of such scheme is that identical or very similar elements of \(h\) are scored equally regardless of their position in the sequence.
Often this issue is partially alleviated by an encoder such as e.g. a BiRNN or a deep convolutional network that encode contextual information into every element of h . However, capacity of h elements is always limited, and thus disambiguation by context is only possible to a limited extent.
- Limitations:
- Location-based Attention: \(\alpha_i = \text{Attend}(s_{i-1}, \alpha_{i-1})\)
a location-based attention mechanism computes the alignment from the generator state and the previous alignment only.- Limitations:
the model would have to predict the distance between consequent phonemes using \(s_{i−1}\) only, which we expect to be hard due to large variance of this quantity.
- Limitations:
- Thus, we conclude that the Hybrid Attention mechanism is a suitable candidate.
Ideally, we need an attention model that uses the previous alignment \(\alpha_{i-1}\) to select a short list of elements from \(h\), from which the content-based attention, will select the relevant ones without confusion.
-
- Preparing the Data (Pre-Processing):
- The paper uses spectrograms as a minimal preprocessing scheme.
-
- Architecture:
- Start with the ARSG-based model:
- Encoder: is a Bi-RNN
$$e_{i,j} = w^T \tanh (Ws_{i-1} + Vh_j + b)$$
- Attention: Content-Based Attention extended for location awareness
$$e_{i,j} = w^T \tanh (Ws_{i-1} + Vh_j + Uf_{i,j} + b)$$
- Extending the Attention Mechanism:
Content-Based Attention extended for location awareness by making it take into account the alignment produced at the previous step.- First, we extract \(k\) vectors \(f_{i,j} \in \mathbb{R}^k\) for every position \(j\) of the previous alignment \(\alpha_{i−1}\) by convolving it with a matrix \(F \in \mathbb{R}^{k\times r}\):
$$f_i = F * \alpha_{i-1}$$
- These additional vectors \(f_{i,j} are then used by the scoring mechanism\)e_{i,j}$$:
$$e_{i,j} = w^T \tanh (Ws_{i-1} + Vh_j + Uf_{i,j} + b)$$
- First, we extract \(k\) vectors \(f_{i,j} \in \mathbb{R}^k\) for every position \(j\) of the previous alignment \(\alpha_{i−1}\) by convolving it with a matrix \(F \in \mathbb{R}^{k\times r}\):
-
- Algorithm:
-
- Issues/The Bottleneck:
A Neural Transducer
Deep Speech 2
-
- Introduction:
- This paper improves on the previous attempt at an End-to-End system for ASR. It increases the complexity of the architecture and is able to achieve high accuracy on two different languages – English and Chinese.
-
- Structure:
-
- Input: vector of speech spectrograms
- An utterance \(x^{(i)}\): is a time-series of length \(T^{(i)}\) composed of time-slices where each is a vector of audio (spectrogram) features \(x_{t,p}^{(i)}, t=1,...,T^{(i)}\), where \(p\) denotes the power of the p’th frequency bin in the audio frame at time \(t\).
- Output: English text transcript \(y\)
- Input: vector of speech spectrograms
-
- Goal:
The goal of the RNN is to convert an input sequence \(x\) into a sequence of character probabilities for the transcription \(y\), with \(\tilde{y}_t = P(c_t\vert x)\), where \(c_t \in \{\text{a, b, c, } \ldots \text{, z, space, apostrophe, blank}\}\).
- Goal:
-
- Strategy:
- The goal is to replace the multi-part model with a single RNN network that captures as much of the information needed to do transcription in a single system.
-
- Solves:
-
- Previous models only used DNNs as a single component in a complex pipeline.
NNs are trained to classify individual frames of acoustic data, and then, their output distributions are reformulated as emission probabilities for a HMM.
In this case, the objective function used to train the networks is therefore substantially different from the true performance measure (sequence-level transcription accuracy.
This leads to problems where one system might have an improved accuracy rate but the overall transcription accuracy can still decrease. - An additional problem is that the frame-level training targets must be inferred from the alignments determined by the HMM. This leads to an awkward iterative procedure, where network retraining is alternated with HMM re-alignments to generate more accurate targets.
- Previous models only used DNNs as a single component in a complex pipeline.
-
- Key Insights:
-
- As an End-to-End model, this system avoids the problems of multi-part systems that lead to inconsistent training criteria and difficulty of integration.
The network is trained directly on the text transcripts: no phonetic representation (and hence no pronunciation dictionary or state tying) is used. - Using CTC objective, the system is able to better approximate and solve the alignment problem avoiding HMM realignment training.
Since CTC integrates out over all possible input-output alignments, no forced alignment is required to provide training targets. - The Dataset is augmented with newly synthesized data and modified to include all the variations and effects that face ASR problems.
This greatly increases the system performance on particularly noisy/affected speech.
- As an End-to-End model, this system avoids the problems of multi-part systems that lead to inconsistent training criteria and difficulty of integration.
-
- Preparing Data (Pre-Processing):
- The paper uses spectrograms as a minimal preprocessing scheme.
-
- Architecture:
- The system is composed of:
- An RNN:
- 5 layers of hidden units:
- 3 Layer of Feed-forward Nets:
- For the input layer, the output depends on the spectrogram frame \(x_t\) along with a context of \(C\) frames on each side.
\[C \in \{5, 7, 9\}\]
- The non-recurrent layers operate on independent data for each time step:
\(h_t^{(l)} = g(W^{(l)} h_{(t)}^{(l-1)} + b^{(l)}),\)
where \(g(z) = \min \{\max \{0, z\}, 20\}\) is the clipped RELU.
- For the input layer, the output depends on the spectrogram frame \(x_t\) along with a context of \(C\) frames on each side.
- 2 layers of Recurrent Nets:
- 1 layer of a Bi-LSTM:
- Includes two sets of hidden units:
A set with forward recurrence \(h^{(f)}\)
A set with backward recurrence \(h^{(b)}\):
\(h_t^{(f)} = g(W^{(4)}h_t^{(3)} + W_r^{(b)} h_{t-1}^{(b)} + b ^{(4)}) \\ h_t^{(b)} = g(W^{(4)}h_t^{(3)} + W_r^{(b)} h_{t+1}^{(b)} + b ^{(4)})\)Note that \(h^{(f)}\) must be computed sequentially from \(t = 1\) to \(t = T^{(i)}\) for the i’th utterance, while the units \(h^{(b)}\) must be computed sequentially in reverse from \(t = T^{(i)}\) to \(t = 1\).
- Includes two sets of hidden units:
A set with forward recurrence \(h^{(f)}\)
- 1 layer of Feed-forward Nets:
- The fifth (non-recurrent) layer takes both the forward and backward units as inputs:
\(h_t^{(5)} = g(W ^{(5)}h_t ^{(4)} + b ^{(5)}),\)
where \(h_t^{(4)} = h_t^{(f)} + h_t^{(b)}\)
- The fifth (non-recurrent) layer takes both the forward and backward units as inputs:
- 1 layer of a Bi-LSTM:
- 3 Layer of Feed-forward Nets:
- An Output layer made of a standard softmax function that yields the predicted character probabilities for each time-slice \(t\) and character \(k\) in the alphabet:
\(\displaystyle{h _{(t,k)} ^{(6)} = \hat{y} _{(t,k)} = P(c_t = k \vert x) = \dfrac{\exp (W_k ^{(6)} h_t ^{(5)} + b_k ^{(6)})}{\sum_j \exp (W_j ^{(6)}h_t ^{(5)} + b_j ^{(6)})}},\)
where \(W_k ^{(6)}\) and \(b_k ^{(6)}\) denote the k’th column of the weight matrix and k’th bias.
- 5 layers of hidden units:
- A CTC Loss Function \(\mathcal{L}(\hat{y}, y)\)
- An N-gram Language Model
- A combined Objective Function:
- An RNN:
- \[Q(c) = \log (P(x \vert x)) + \alpha \log (P_{\text{LM}}(c) + \beta \text{word_count}(c))\]
-
- Algorithm:
-
- Given the output \(P(c \vert x)\) of the RNN: perform a search to find the sequence of characters \(c_1, c_2, ...\) that is most probable according to both:
- The RNN Output
- The Language Model
- We maximize the combined objective:
\(Q(c) = \log (P(x \vert x)) + \alpha \log (P_{\text{LM}}(c) + \beta \text{word_count}(c))\)
where the term \(P_{\text{lm}} denotes the probability of the sequence\)c$$ according to the N-gram model. - The objective is maximized using a highly optimized beam search algorithm
beam size: 1000-8000
- Given the output \(P(c \vert x)\) of the RNN: perform a search to find the sequence of characters \(c_1, c_2, ...\) that is most probable according to both:
-
- Training:
-
- The gradient of the CTC Loss \(\nabla_{\hat{y}} \mathcal{L}(\hat{y}, y)\) with respect to the net outputs given the ground-truth character sequence \(y\) is computed
-
- Nesterov’s Accelerated gradient
- Nesterov Momentum
- Annealing the learning rate by a constant factor
- Dropout
- Striding – shortening the recurrent layers by taking strides of size \(2\).
The unrolled RNN will have half as many steps.similar to a convolutional network with a step-size of 2 in the first layer.
-
- Parameters:
-
- Momentum: \(0.99\)
- Dropout: \(5-10 \%\) (FFN only)
- Trade-Off Params: use cross-validation for \(\alpha, \beta\)
-
- Issues/The Bottleneck:
-
- Results:
-
- SwitchboardHub5’00 (
WER):
- Standard: \(16.0\%\)
- w/Lexicon of allowed words: \(21.9\%\)
- Trigram LM: \(8.2\%\)
- w/Baseline system: \(6.7\%\)
- SwitchboardHub5’00 (
WER):
-
- Discussion:
-
- Why avoid LSTMs:
One disadvantage of LSTM cells is that they require computing and storing multiple gating neuron responses at each step.
Since the forward and backward recurrences are sequential, this small additional cost can become a computational bottleneck.
- Why avoid LSTMs:
-
- Why a homogeneous model:
By using a homogeneous model we have made the computation of the recurrent activations as efficient as possible: computing the ReLu outputs involves only a few highly optimized BLAS operations on the GPU and a single point-wise nonlinearity.
- Why a homogeneous model:
-
- Further Development:
Listen, Attend and Spell (LAS)
-
- Introduction:
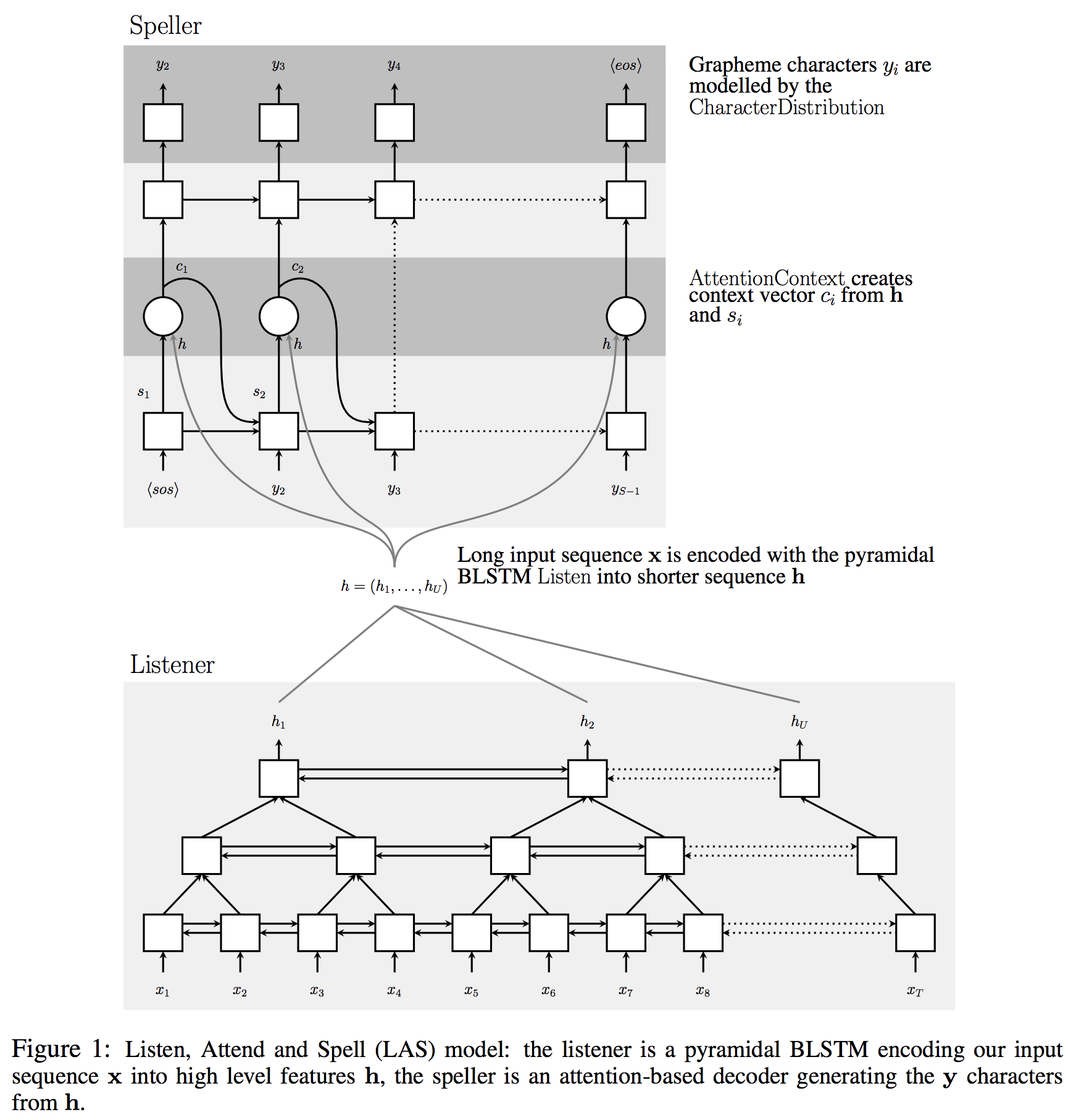
- This paper presents a a neural network that learns to transcribe speech utterances to characters. Unlike traditional DNN-HMM models, this model learns all the components of a speech recognizer jointly.
- The system has two components: a listener and a speller.
- LAS is based on the sequence to sequence learning framework with attention.
-
- Structure:
-
-
Input: \(\mathbb{x} = (x_1, \ldots, x_T)\) a sequence of filter bank spectra (acoustic) features
-
Output: \(\mathbb{y} = (\text{<sos>}, y_1, \ldots, y_S, \text{<eos>}), y_i \in \{\text{a, b, c, · · · , z, 0, · · · , 9, <spacei,<comma>,<period>,<apostrophe>,<unk> }\}\) the output sequence of characters
-
-
- Goal:
The goal of the RNN is to convert an input sequence \(x\) into a sequence of character probabilities for the transcription \(y\), with \(\tilde{y}_t = P(c_t\vert x)\), where \(c_t \in \{\text{a, b, c, } \ldots \text{, z, space, apostrophe, blank}\}\).
- Goal:
-
- Strategy:
- LAS is based on the sequence to sequence learning framework with attention.
-
- We want to model each character output \(y_i\) as a conditional distribution over the previous characters \(y_{\leq i+1}\) and the input signal \(\mathbb{x}\) using the chain rule:
$$P(\mathbb{y} \vert \mathbb{x}) = \prod_i P(y_i \vert \mathbb{x}, y_{\leq i+1}) \:\:\:\: (1)$$
-
- Solves:
-
- CTC:
CTC assumes that the label outputs are conditionally independent of each other - Seq2Seq:
the sequence to sequence approach has only been applied to phoneme sequences, and not trained end-to-end for speech recognition.
- CTC:
-
- Key Insights:
-
- Use a pyramidal RNN model for the listener, which reduces the number of time steps that the attention model has to extract relevant information from.
The pyramid structure also reduces the computational complexity. - Character-based transcription allows the handling of rare and OOV words automatically
- Attention
- Use a pyramidal RNN model for the listener, which reduces the number of time steps that the attention model has to extract relevant information from.
-
- The Model:
- Listen:
Uses a Bi-directional LSTM with a pyramid structure.The pyramid structure is needed to reduce the length \(U\) of \(\mathbf{h}\), from \(T\) , the length of the input \(\mathbb{h}\) , because the input speech signals can be hundreds to thousands of frames long.
- Pyramidal LSTM:
The output at the i-th time step, from the j-th layer is changed from:$$h_i^j = \text{BLSTM}(h_{i-1}^j, h_{i}^{j-1})$$
to, instead, we concatenate the outputs at consecutive steps of each layer before feeding it to the next layer:
$$h_i^j = \text{pBLSTM}(h_{i-1}^j, \left[h_{2i}^{j-1}, h_{2i+1}^{j-1}\right])$$
- In the model, we stack 3 pBLSTMs on top of the bottom BLSTM layer to reduce the time resolution \(2^3 = 8\) times.
- Attend and Spell:
The function is computed using an attention-based LSTM transducer.
At every output step, the transducer produces a probability distribution over the next character conditioned on all the characters seen previously.
The distribution for \(y_i\) is a function of the decoder state \(s_i\) and context \(c_i\).
The decoder state \(s_i\) is a function of the previous state \(s_{i−1}\), the previously emitted character \(y_{i−1}\) and context \(c_{i−1}\).
The context vector \(c_i\) is produced by an attention mechanism:
$$ c_i = \text{AttentionContext}(s_i, \mathbf{h}) \\ s_i = \text{RNN}(s_{i-1}, y_{i-1}, c_{i-1}) \\ P(y_i \vert \mathbf{x}, y_{\leq i+1}) = \text{CharacterDistribution}(s_i, c_i)$$
where CharacterDistribution is an MLP with softmax outputs over characters, and RNN is a 2 layer LSTM.
The Attention Mechanism:
At each step \(i\), the attention mechanism, AttentionContext generates a context vector \(c_i\) encapsulating the information in the acoustic signal needed to generate the next character.
The attention model is content based - the contents of the decoder state \(s_i\) are matched to the contents of \(h_u\) representing time step \(u\) of \(\mathbf{h}\) to generate an attention vector \(\alpha_i\).
\(\alpha_i\) is used to linearly blend vectors \(h_u\) to create \(c_i\).
Specifically, at each decoder timestep \(i\) , the AttentionContext function computes the scalar energy \(e_{i,u}\) for each time step \(u\) , using vector \(h_u \in h\) and \(s_i\).
The scalar energy \(e_{i,u}\) is converted into a probability distribution over times steps (or attention) \(\alpha_i\) using a softmax function. This is used to create the context vector \(c_i\) by linearly blending the listener features, \(h_u\), at different time steps:$$\begin{align} e_{i,u} &= <\phi(s_i), \psi(h_u)> \\ \alpha_{i,u} &= \dfrac{\exp(e_{i,u})}{\sum_u \exp(e_{i,u})} \\ c_i &= \sum_u \alpha_{i,u}h_u \end{align} $$
where \(\phi\) and \(\psi\) are MLP Networks.
On convergence, the \(\alpha_i\) distribution is typically very sharp, and focused on only a few frames of \(\mathbf{h}\) ; \(c_i\) can be seen as a continuous bag of weighted features of \(\mathbf{h}\). -
Preparing Data (Pre-Processing):
-
- Architecture:
-
- Encoder (listener):
An acoustic model encoder, whose key operation isListen.
It converts low level speech signals into higher level features.- (pyramidal) RNN:
-
Bi-Directional LSTM:
- Structure:
- Input: original signal \(\mathbb{x}\)
- Output: a high level representation \(\mathbf{h} = (h_1, ]ldots, h_U)\), with \(U \leq T\)
- Structure:
-
- (pyramidal) RNN:
- Decoder (speller):
The speller is an attention-based character decoder, whose key operation isAttendAndSpell.
It converts the higher level features into output utterances by specifying a probability distribution over sequences of characters using the attention mechanism.- RNN:
- Structure:
- Input: features \(\mathbf{h}\)
- Output: a probability distribution over character sequences: \(\mathbf{h} = (h_1, ]ldots, h_U)\), with \(U \leq T\)
- Structure:
- RNN:
- Encoder (listener):
-
- Algorithm:
-
- Training:
-
- The gradient of the CTC Loss \(\nabla_{\hat{y}} \mathcal{L}(\hat{y}, y)\) with respect to the net outputs given the ground-truth character sequence \(y\) is computed
-
- Nesterov’s Accelerated gradient
- Nesterov Momentum
- Annealing the learning rate by a constant factor
- Dropout
- Striding – shortening the recurrent layers by taking strides of size \(2\).
The unrolled RNN will have half as many steps.similar to a convolutional network with a step-size of 2 in the first layer.
-
Inference (Decoding and Rescoring):
-
- Parameters:
-
- Momentum: \(0.99\)
- Dropout: \(5-10 \%\) (FFN only)
- Trade-Off Params: use cross-validation for \(\alpha, \beta\)
-
- Issues/The Bottleneck:
-
- Results:
-
- SwitchboardHub5’00 (
WER):
- Standard: \(16.0\%\)
- w/Lexicon of allowed words: \(21.9\%\)
- Trigram LM: \(8.2\%\)
- w/Baseline system: \(6.7\%\)
- SwitchboardHub5’00 (
WER):
-
- Discussion:
-
- Without the attention mechanism, the model overfits the training data significantly, in spite of our large training set of three million utterances - it memorizes the training transcripts without paying attention to the acoustics.
- Without the pyramid structure in the encoder side, our model converges too slowly - even after a month of training, the error rates were significantly higher than the errors reported
- To reduce the overfitting of the speller to the training transcripts, use a sampling trick during training
-
- Further Development: