W2V Detailed Tutorial - Skip Gram (Stanford)
W2V Detailed Tutorial - Negative Sampling (Stanford)
Commented word2vec C code
W2V Resources
An overview of word embeddings and their connection to distributional semantic models
On Word Embeddings (Ruder)
- Eigenwords: Spectral Word Embeddings (paper!)
- Stop Using word2vec (blog)
- Word2vec Inspired Recommendations In Production (blog)
Word Meaning
-
Representing the Meaning of a Word:
Commonest linguistic way of thinking of meaning:
Signifier \(\iff\) Signified (idea or thing) = denotation -
How do we have usable meaning in a computer:
Commonly: Use a taxonomy like WordNet that has hypernyms (is-a) relationships and synonym sets - Problems with this discrete representation:
- Great as a resource but missing nuances:
- Synonyms:
adept, expert, good, practiced, proficient, skillful
- Synonyms:
- Missing New Words
- Subjective
- Requires human labor to create and adapt
- Hard to compute accurate word similarity:
- One-Hot Encoding: in vector space terms, this is a vector with one 1 (at the position of the word) and a lot of zeroes (elsewhere).
- It is a localist representation
- There is no natural notion of similarity in a set of one-hot vectors
- One-Hot Encoding: in vector space terms, this is a vector with one 1 (at the position of the word) and a lot of zeroes (elsewhere).
- Great as a resource but missing nuances:
-
Distributed Representations of Words:
A method where vectors encode the similarity between the words.The meaning is represented with real-valued numbers and is “smeared” across the vector.
Contrast with one-hot encoding.
-
Distributional Similarity:
is an idea/hypothesis that one can describe the meaning of words by the context in which they appear in.Contrast with Denotational Meaning of words.
-
The Big Idea:
We will build a dense vector for each word type, chosen so that it is good at predicting other words appearing in its context. - Learning Neural Network Word Embeddings:
We define a model that aims to predict between a center word \(w_t\) and context words in terms of word vectors.$$p(\text{context} \vert w_t) = \ldots$$
The Loss Function:
$$J = 1 - p(w_{-t} \vert w_t)$$
We look at many positions \(t\) in a big language corpus
We keep adjusting the vector representations of words to minimize this loss - Relevant Papers:
- Learning representations by back-propagating errors (Rumelhart et al., 1986)
- A neural probabilistic language model (Bengio et al., 2003)
- NLP (almost) from Scratch (Collobert & Weston, 2008)
- A recent, even simpler and faster model: word2vec (Mikolov et al. 2013) à intro now
Word Embeddings
- Main Ideas:
- Words are represented as vectors of real numbers
- Words with similar vectors are semantically similar
- Sometimes vectors are low-dimensional compared to the vocabulary size
- The Clusterings:
Relationships (attributes) Captured:- Synonyms: car, auto
- Antonyms: agree, disagree
- Values-on-a-scale: hot, warm, cold
- Hyponym-Hypernym: “Truck” is a type of “car”, “dog” is a type of “pet”
- Co-Hyponyms: “cat”&”dog” is a type of “pet”
- Context: (Drink, Eat), (Talk, Listen)
-
Word Embeddings Theory:
Distributional Similarity Hypothesis -
History and Terminology:
Word Embeddings = Distributional Semantic Model = Distributed Representation = Semantic Vector Space = Vector Space Model - Applications:
- Word Similarity
- Word Grouping
- Features in Text-Classification
- Document Clustering
- NLP:
- POS-Tagging
- Semantic Analysis
- Syntactic Parsing
- Approaches:
- Count: word count/context co-occurrences
- Distributional Semantics:
- Summarize the occurrence statistics for each word in a large document set:

- Apply some dimensionality reduction transformation (SVD) to the counts to obtain dense real-valued vectors:
- Compute similarity between words as vector similarity:
- Summarize the occurrence statistics for each word in a large document set:
- Distributional Semantics:
- Predict: word based on context
- word2vec:
- In one setup, the goal is to predict a word given its context.
- Update word representations for each context in the data set
- Similar words would be predicted by similar contexts
- In one setup, the goal is to predict a word given its context.
- word2vec:
- Count: word count/context co-occurrences
- Parameters:
- Underlying Document Set
- Context Size
- Context Type
- Software:
Word2Vec
-
Word2Vec:
Word2Vec (Mikolov et al. 2013) is a framework for learning word representations as vectors. It is based on the idea of distributional similarity.
- Main Idea:
- Given a large corpus of text
- Represent every word, in a fixed vocabulary, by a vector
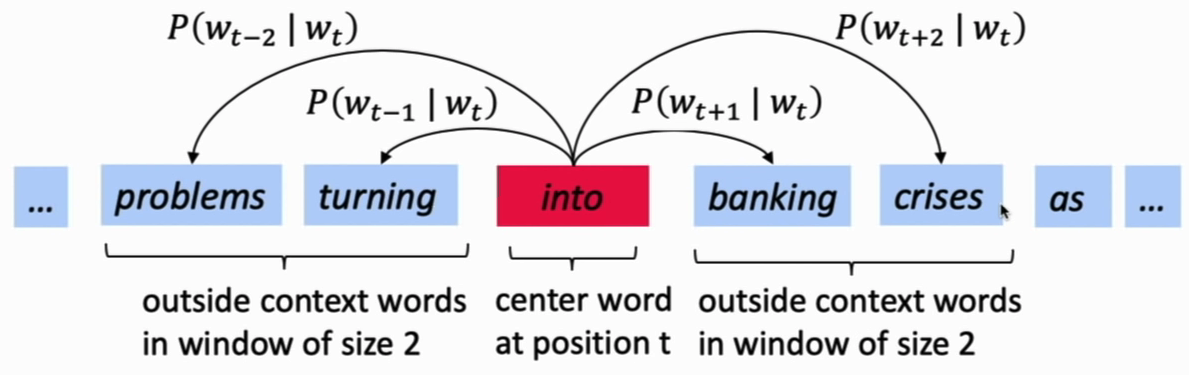
- Go through each position \(t\) in the text, which has a center word \(c\) and context words \(o\)
- Use the similarity of the word vectors for \(c\) and \(o\) to calculate the probability of \(o\) given \(c\) (SG)
- Keep adjusting the word vectors to maximize this probability
- Algorithms:
- Skip-grams (SG):
Predict context words given target (position independent) - Continuous Bag of Words (CBOW):
Predict target word from bag-of-words context
- Skip-grams (SG):
- Training Methods:
- Basic:
- Naive Softmax
- (Moderately) Efficient:
- Hierarchical Softmax
- Negative Sampling
- Basic:
- Skip-Gram Prediction Method:
Skip-Gram Models aim to predict the distribution (probability) of context words from a center word.CBOW does the opposite, and aims to predict a center word from the surrounding context in terms of word vectors.
The Algorithm:
- We generate our one hot input vector \(x \in \mathbf{R}^{\vert V\vert }\) of the center word.
- We get our embedded word vector for the center word \(v_c = V_x \in \mathbf{R}^n\)
- Generate a score vector \(z = \mathcal{U}_ {v_c}\)
- Turn the score vector into probabilities, \(\hat{y} = \text{softmax}(z)\)
Note that \(\hat{y}_{c−m}, \ldots, \hat{y}_{c−1}, \hat{y}_{c+1}, \ldots, \hat{y}_{c+m}\) are the probabilities of observing each context word.
- We desire our probability vector generated to match the true probabilities, which is
\(y^{(c−m)} , \ldots, y^{(c−1)} , y^{(c+1)} , \ldots, y^{(c+m)}\),
the one hot vectors of the actual output.
- Word2Vec Details:
- For each word (position) \(t = 1 \ldots T\), predict surrounding (context) words in a window of “radius” \(m\) of every word.
Calculating \(p(o \vert c)\)1 the probability of outside words given center word:
- We use two vectors per word \(w\):
- \(v_{w}\): \(\:\) when \(w\) is a center word
- \(u_{w}\): \(\:\) when \(w\) is a context word
- Now, for a center word \(c\) and a context word \(o\), we calculate the probability:
$$\\{\displaystyle p(o \vert c) = \dfrac{e^{u_o^Tv_c}}{\sum_{w\in V} e^{u_w^Tv_c}}} \:\:\:\:\:\:\:\:\:\:\:\:\\$$
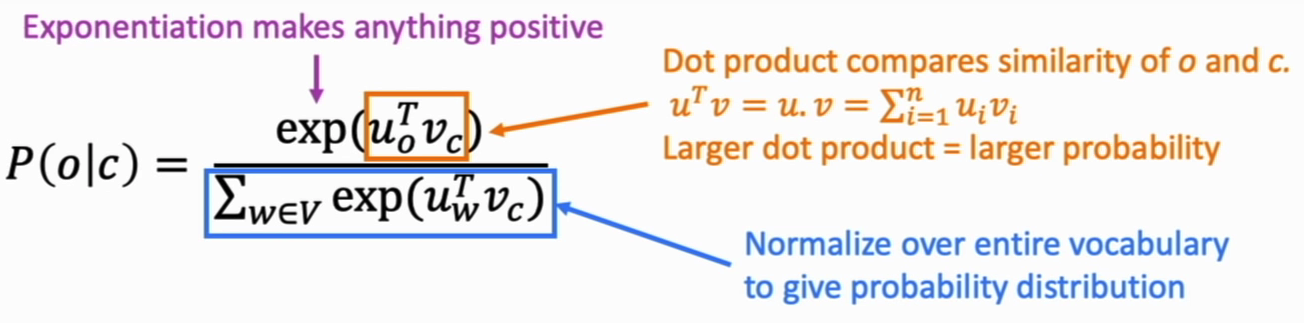
- The Probability Distribution \(p(o \vert c)\) is an application of the softmax function on the, dot-product, similarity function \(u_o^Tv_c\)
- The Softmax function, allows us to construct a probability distribution by making the numerator positive, and normalizing the function (to \(1\)) with the denominator
- The similarity function \(u_o^Tv_c\) allows us to model as follows: the more the similarity \(\rightarrow\) the larger the dot-product; the larger the exponential in the softmax
-
The Objective:
Goal:
Maximize the probability of any context word given the current center word.We start with the Likelihood of being able to predict the context words given center words and the parameters \(\theta\) (only the wordvectors).
The Likelihood:$$L(\theta)=\prod_{t=1}^{T} \prod_{-m \leq j \leq m \atop j \neq 0} P\left(w_{t+j} | w_{t} ; \theta\right)$$
The objective:
The Objective is just the (average) negative log likelihood:$$J(\theta) = -\frac{1}{T} \log L(\theta)= - \dfrac{1}{T} \sum_{t=1}^{t} \sum_{-m \leq j \leq m \\ \:\:\:\:j\neq 0} \log p(w_{t+j} \vert w_t ; \theta))$$
Notice: Minimizing objective function \(\iff\) Maximizing predictive accuracy2
-
The Gradients:
We have a vector of parameters \(\theta\) that we are trying to optimize over, and We need to calculate the gradient of the two sets of parameters in \(\theta\); namely, \(\dfrac{\partial}{\partial v_c}\) and \(\dfrac{\partial}{\partial u_o}\).The gradient \(\dfrac{\partial}{\partial v_c}\):
$$\dfrac{\partial}{\partial v_c} \log p(o\vert c) = u_o - \sum_{w'\in V} p{(w' | c)} \cdot u_{w'}$$
Interpretation:
We are getting the slope by: taking the observed representation of the context word and subtracting away (“what the model thinks the context should look like”) the weighted average of the representations of each word multiplied by its probability in the current model
(i.e. the Expectation of the context word vector i.e. the expected context word according to our current model)I.E.
The difference between the expected context word and the actual context wordImportance Sampling:
$$\sum_{w_{i} \in V} \left[\frac{\exp \left(-\mathcal{E}\left(w_{i}\right)\right)}{\sum_{w_{i} \in V} \exp \left(-\mathcal{E}\left(w_{i}\right)\right)}\right] \nabla_{\theta} \mathcal{E}\left(w_{i}\right) \\ = \sum_{w_{i} \in V} P\left(w_{i}\right) \nabla_{\theta} \mathcal{E}\left(w_{i}\right)$$
$$\mathbb{E}_{w_{i} \sim P}\left[\nabla_{\theta} \mathcal{E}\left(w_{i}\right)\right] =\sum_{w_{i} \in V} P\left(w_{i}\right) \nabla_{\theta} \mathcal{E}\left(w_{i}\right)$$
- \(P\left(w_{i}\right) \approx \frac{r(w_i)}{R}\),
$$\mathbb{E}_{w_{i} \sim P}\left[\nabla_{\theta} \mathcal{E}\left(w_{i}\right)\right] \approx \sum_{w_{i} \in V} \frac{r(w_i)}{R} \nabla_{\theta} \mathcal{E}\left(w_{i}\right)$$
$$\mathbb{E}_{w_{i} \sim P}\left[\nabla_{\theta} \mathcal{E}\left(w_{i}\right)\right] \approx \frac{1}{R} \sum_{i=1}^{m} r\left(w_{i}\right) \nabla_{\theta} \mathcal{E}\left(w_{i}\right)$$
where \(r(w)=\frac{\exp (-\mathcal{E}(w))}{Q(w)}\), \(R=\sum_{j=1}^{m} r\left(w_{j}\right)\), and \(Q\) is the unigram distribution of the training set.
- Notes:
- Mikolov on SkipGram vs CBOW:
- Skip-gram: works well with small amount of the training data, represents well even rare words or phrases.
- CBOW: several times faster to train than the skip-gram, slightly better accuracy for the frequent words.
- Further Readings:
- Mikolov on SkipGram vs CBOW:
- From ‘concepts’:
Word Vectors:Notes:
- Categorization is a method for Evaluating w2v Embeddings by creating categorize by clustering, then measuring the purity of the clusters
-


Notes:
- Word2vec maximizes the objective by putting similar words close to each other in space
-
pictures from lecture:
w2v:

Softmax:

Training/Optimization:

Optimization - GD:
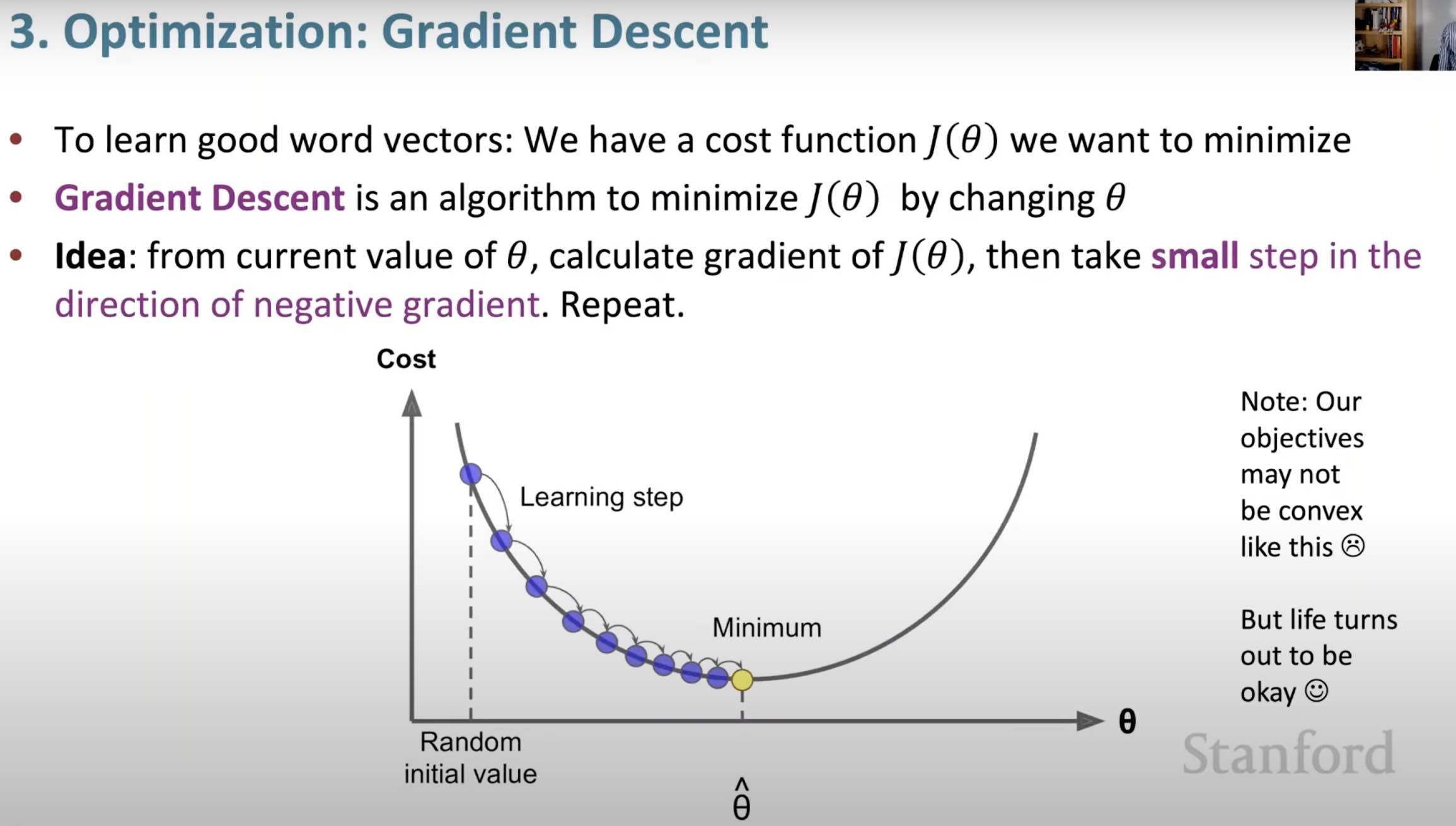
GD {: width="80%"} SGD: 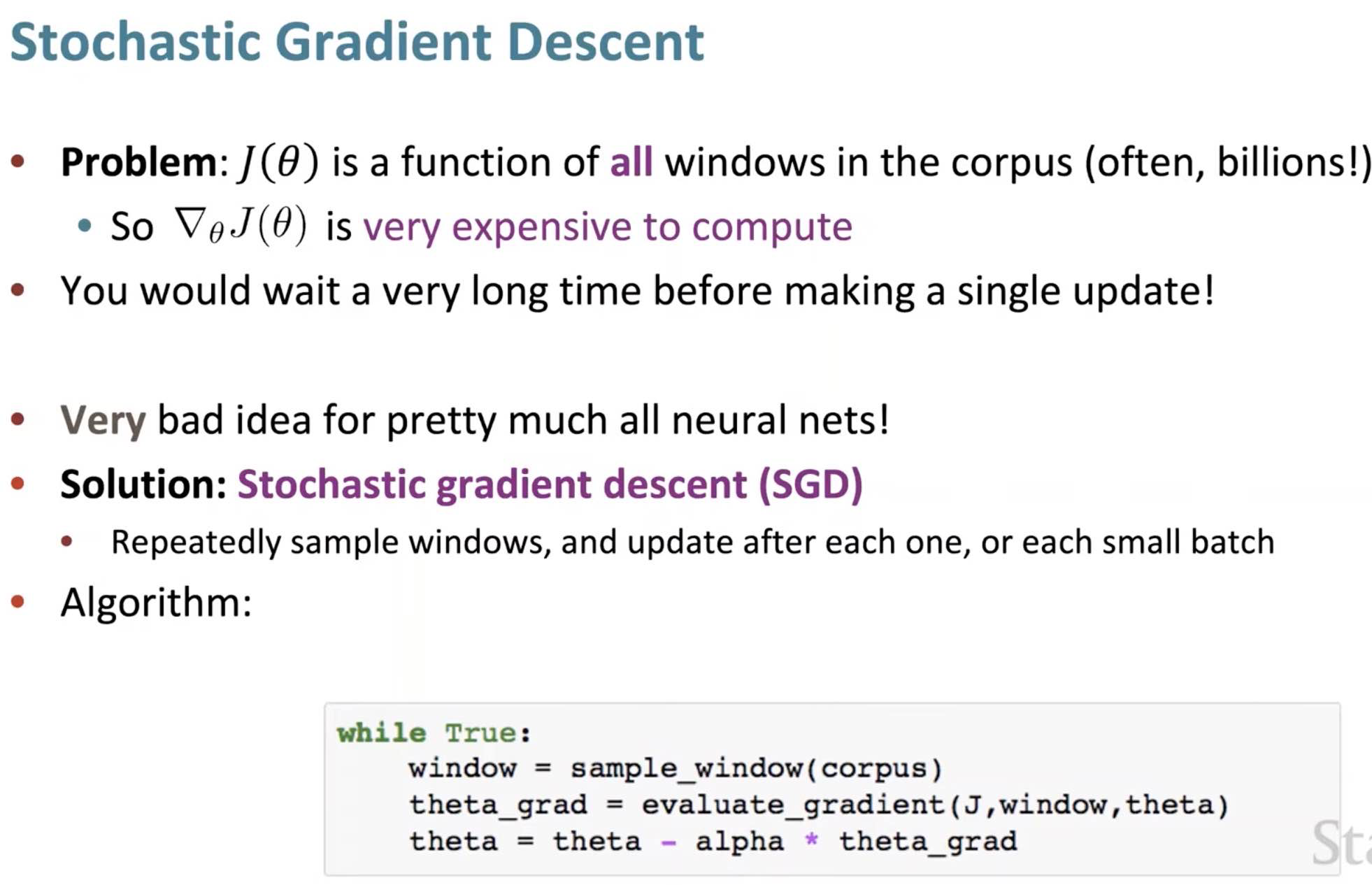{: width="80%"} <button>SGD</button>{: .showText value="show" onclick="showTextPopHide(event);"} {: width="100%" hidden=""} <button>SGD</button>{: .showText value="show" onclick="showTextPopHide(event);"} {: width="100%" hidden=""} Note: rows can be accessed as a _contiguous block in memory_ (so if row is a word, you can access it much more efficiently)



-
Unigram Distribution: A distribution of words based on how many times each word appeared in a corpus is called unigram distribution.

-
Noise Distribution:
-
Optimize Computational Efficiency of Skip-Gram with Negative Sampling (Blog)
-
Demystifying Neural Network in Skip-Gram Language Modeling (Blog!!!!)
-
Understanding Multi-Dimensionality in Vector Space Modeling (Blog!!)
-