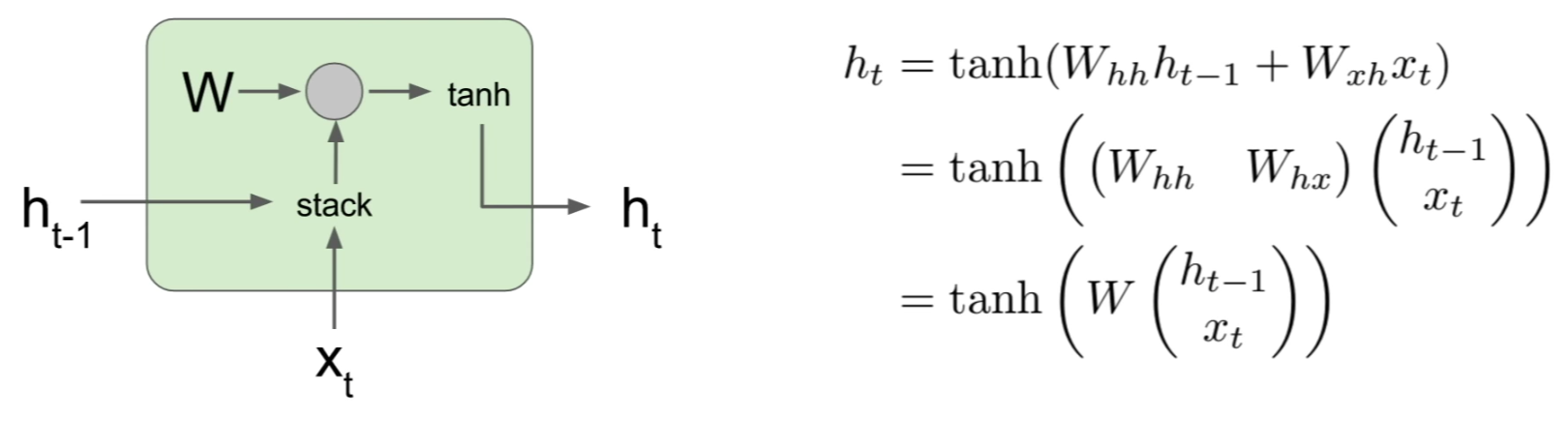RNNs
Refer to this section on RNNs
-
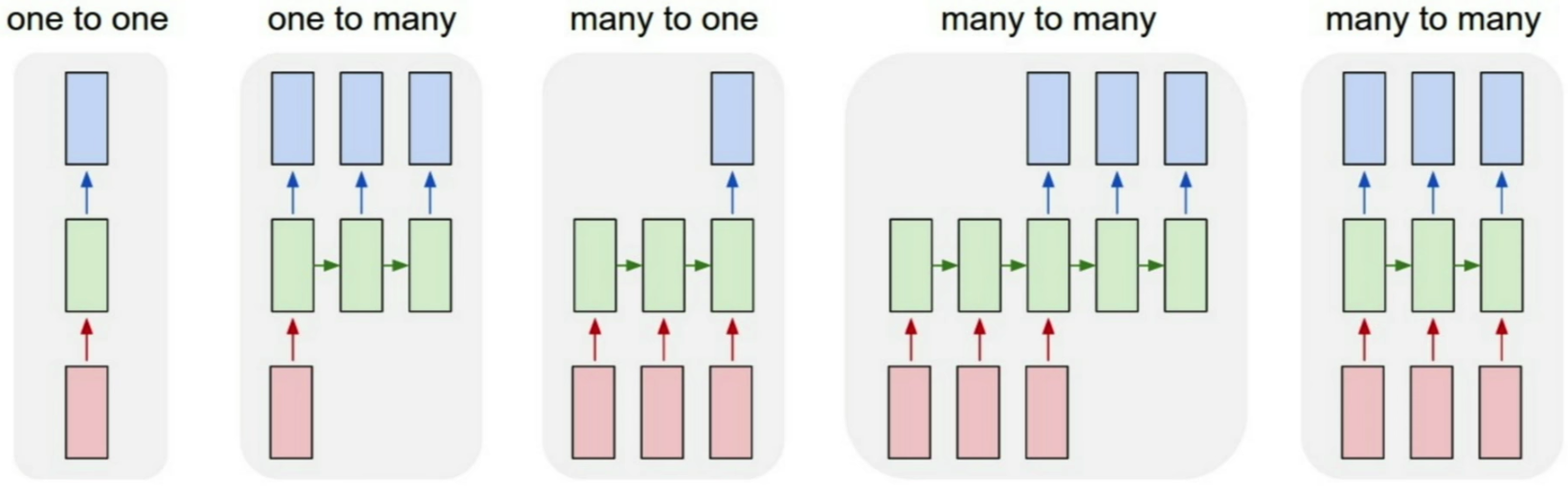
- Process Sequences:
-
- One-to-One
- One-to-Many: Image Captioning: image -> seq of words
- Many-to-One: Sentiment Classification: seq of words -> Sentiment
- Many-to-Many:
Machine Translation: seq of words -> seq of words - (Discrete) Many-to-Many:
Frame-Level Video Classification: seq. of frames -> seq of classes per frame
-
- RNN Structure:
- We can process a sequence of vectors \(\vec{x}\) by applying a recurrence formula__ at every time step:
- \[h_t = f_W(h_{t-1}, x_t)\]
- where \(h_t\) is the new state, \(f_W\) is some function with weights \(W\), \(h_{t-1}\) is the old state, and \(x_t\) is the input vector at some time step \(t\).
The same function and set of parameters (weights) are used at every time step.
-
- A Vanilla Architecture of an RNN:
- \[\begin{align} h_t &= f_W(h_{t-1}, x_t) h_t &= tanh(W_{hh}h_t{t-1} + W_{xh}x_t) y_t &= W_{hy}h_t \end{align}\]
-
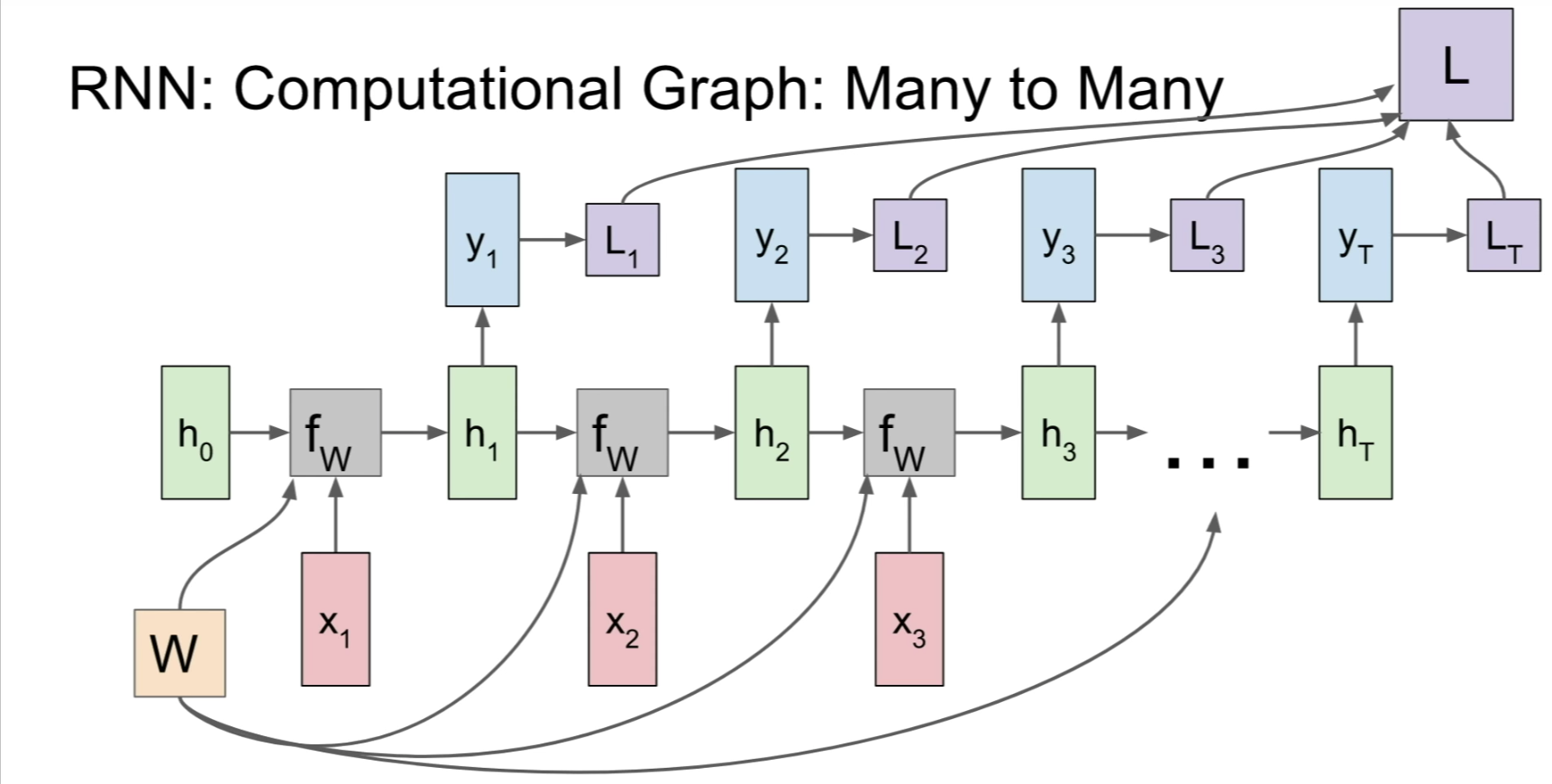
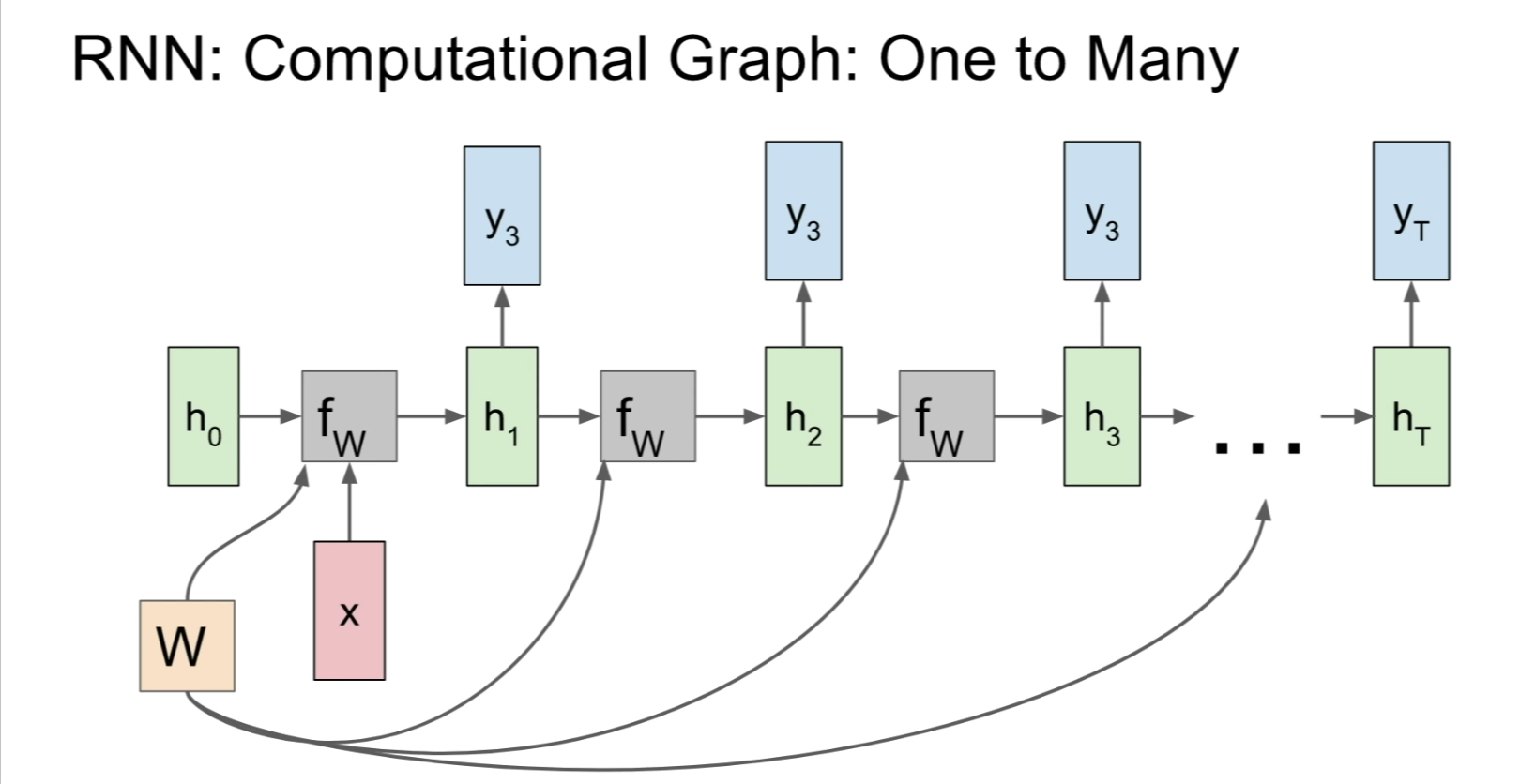
- The RNN Computational Graph:
-
- Many-to-Many:
-
- One-to-Many:
-
- Seq-to-Seq:
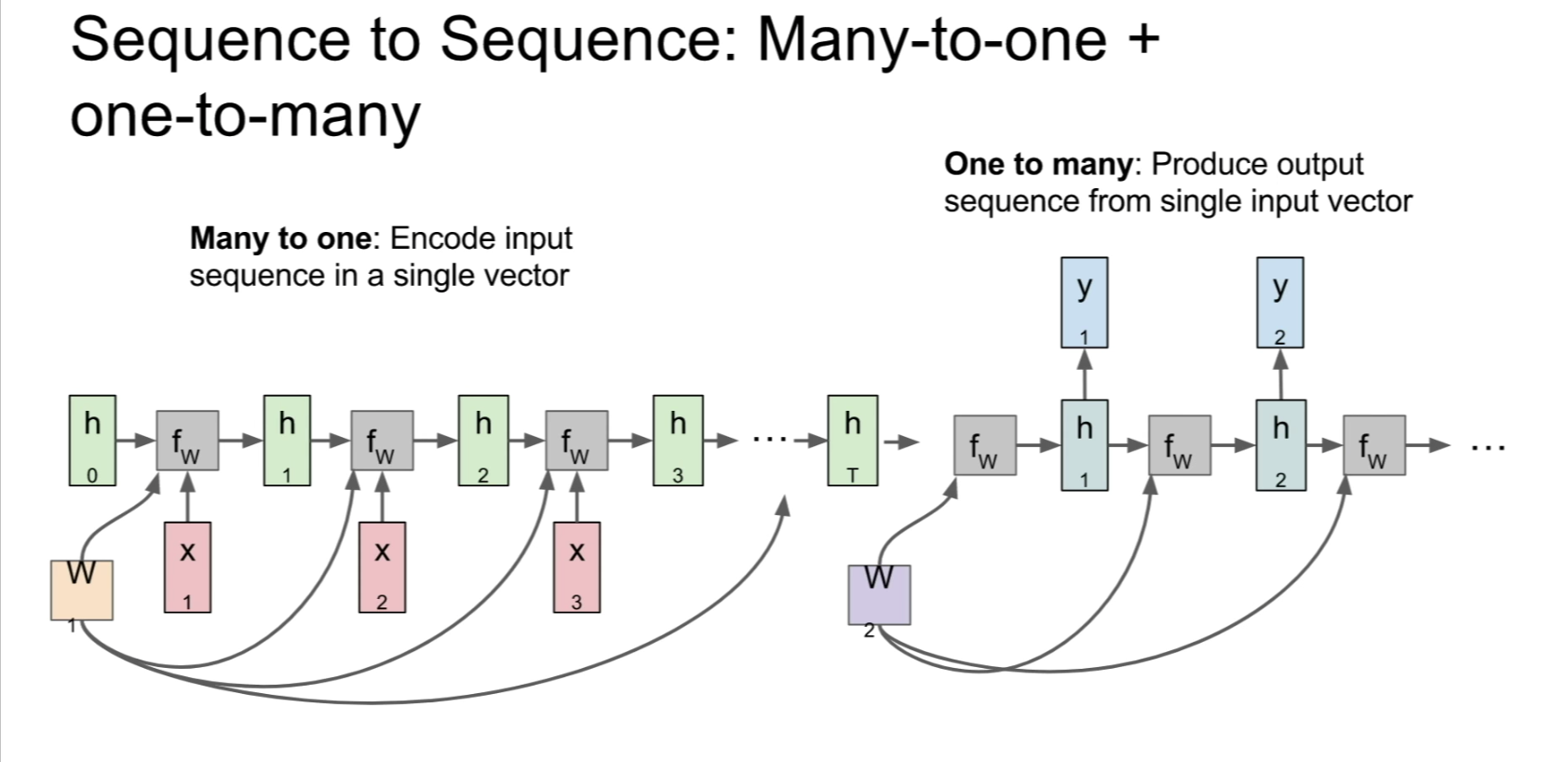
-
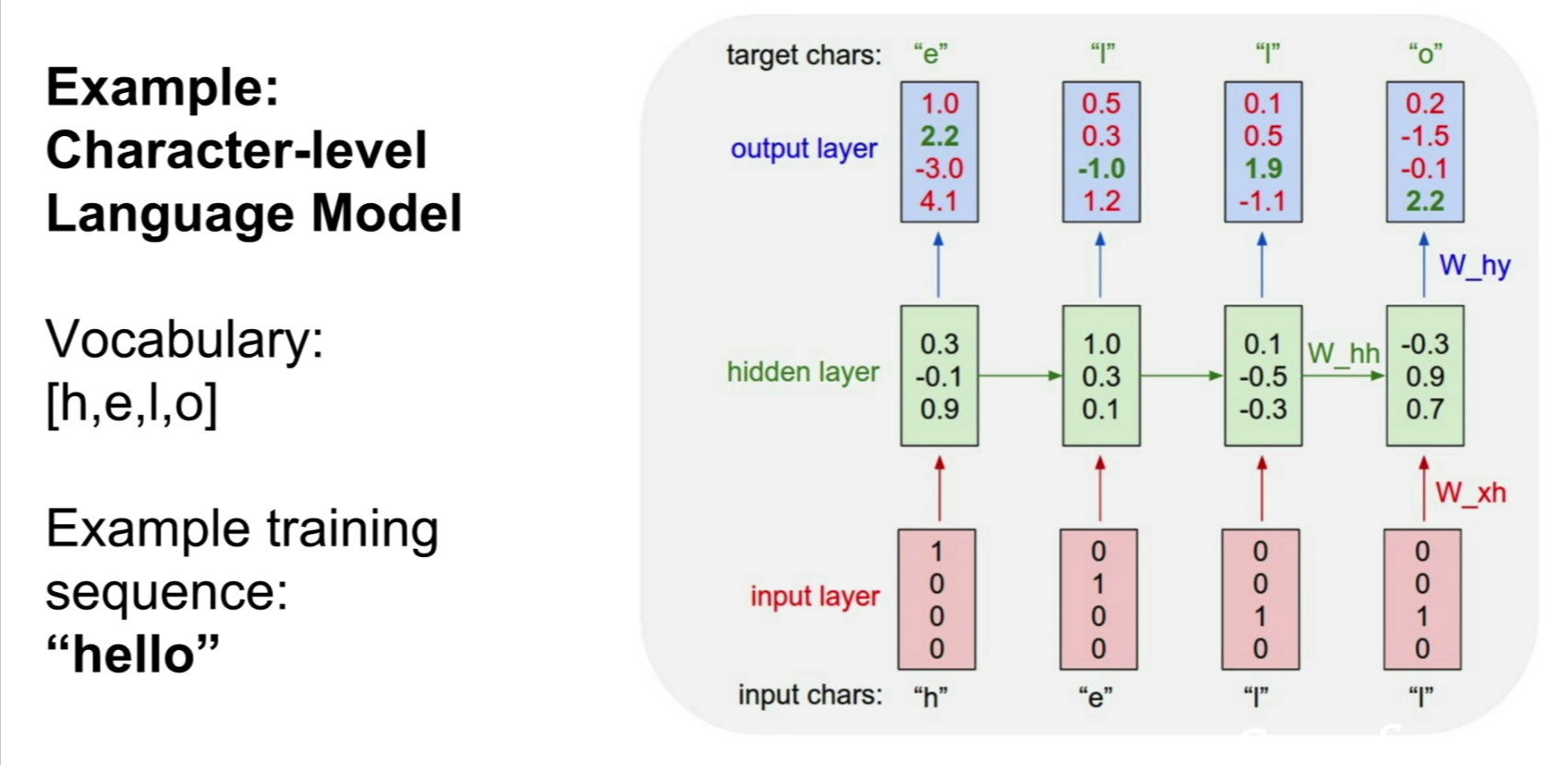
- Example Architecture: Character-Level Language Model:
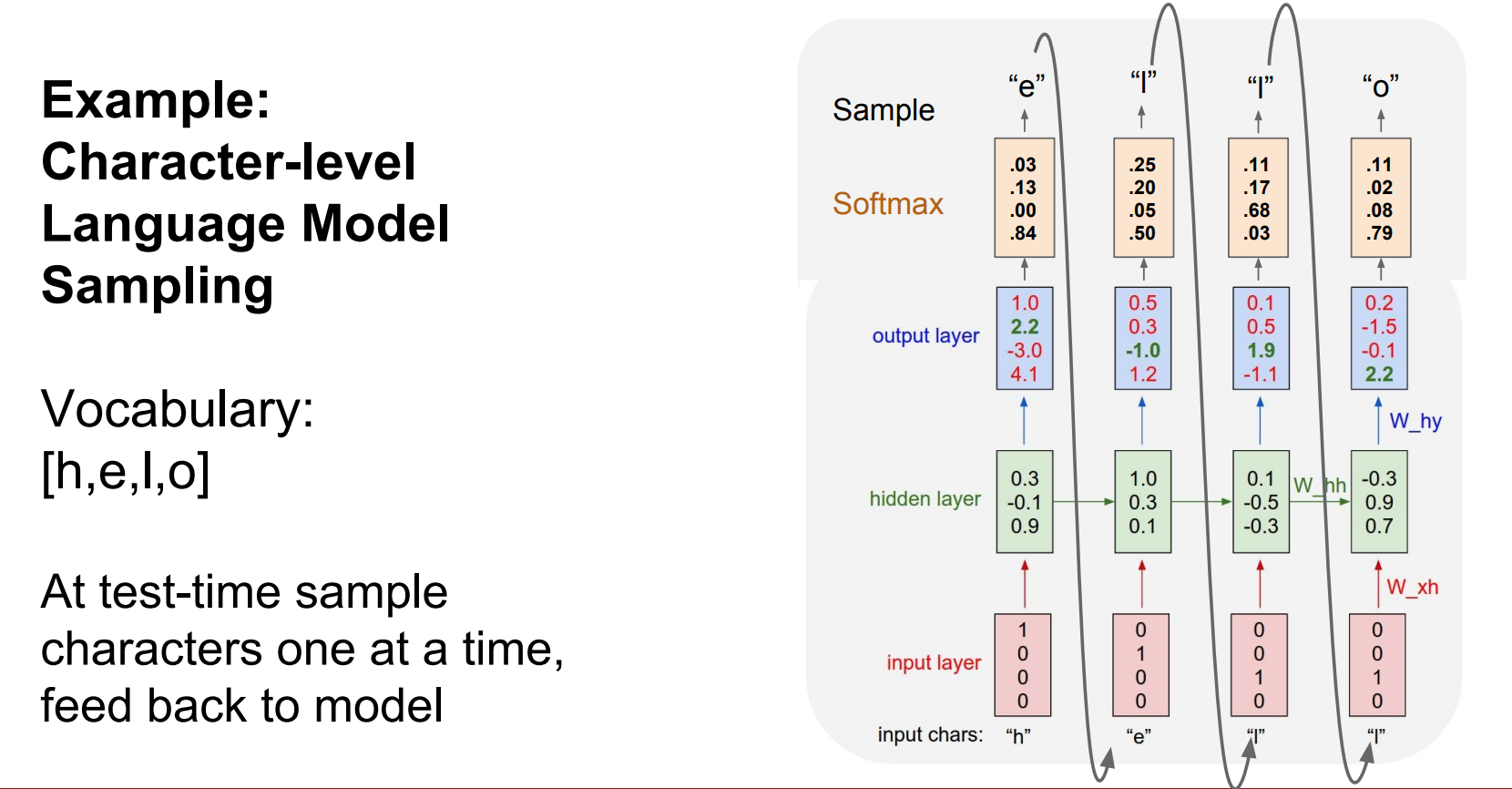
-
- The Functional Form of a Vanilla RNN (Gradient Flow):