Table of Contents
Introduction to Information Extraction
-
- Information Extraction (IE):
- is the task of automatically extracting structured information from a (non/semi)-structured piece of text.
-
- Structured Representations of Inforamtion:
- Usually, the extracted information is represented as:
- Relations (in the DataBase sense)
- A Knowledge Base
-
- Goals:
-
- Organize information in a way that is useful to humans.
- Put information in a semantically precise form that allows further inference to be made by other computer algorithms.
-
- Common Applications:
-
- Gathering information (earning, profits, HQs, etc.) from reports
- Learning drug-gene product interactions from medical research literature
- Low-Level Information Extraction:
- Information about possible dates, schedules, activites gathered by companys (e.g. google, facebook)
-
- Tasks and Sub-tasks:
-
- Named entity extraction:
- Named Entity Recognition: recognition of known entity names (for people and organizations), place names, temporal expressions, and certain types of numerical expressions.
- Coreference Resolution: detection of coreference and anaphoric links between text entities.
- Relationship Extraction: identification of relations between entities.
- Semi-structured information extraction:
- Table Extraction: finding and extracting tables from documents.
- Comments extraction: extracting comments from actual content of article in order to restore the link between author of each sentence.
- Language and Vocabulary Analysis:
- Terminology extraction: finding the relevant terms for a given corpus.
- Named entity extraction:
-
- Methods:
- There are three standard approaches for tackling the problem of IE:
- Hand-written Regular Expressions: usually stacked.
- Classifiers:
- Generative:
- Naive Bayes Classifier
- Discriminative:
- MaxEnt Models (Multinomial Logistic Regr.)
- Generative:
- Sequence Models:
- Hidden Markov Models
- Conditional Markov model (CMM) / Maximum-entropy Markov model (MEMM)
- Conditional random fields (CRF)
Named Entity Recognition (NER)
-
- Named Entity Recognition:
- is the recognition of known entity names (for people and organizations), place names, temporal expressions, and certain types of numerical expressions;
this is usually done by employing existing knowledge of the domain or information extracted from other sentences.
-
- Applications:
-
- Named entities can be indexed, linked off, etc.
- Sentiment can be attributed to companies or products
- They define a lot of the IE relations, as associations between the named entities
- In QA, answers are often named entities
-
- Evaluation of NER Tasks:
- Evaluation is usually done at the level of Entities and not of Tokens.
- One common issue with the metrics defined for text classification, namely, (Precision/Recall/F1) is that they penalize the system based on a binary evaluation on how the system did; however, let’s demonstrate why that would be problamitic.
-
- Consider the following text:
“The First Bank of Chicago announced earnings…”
Let the italic part of the text be the enitity we want to recognize and let the bolded part of the text, be the entitiy that our model identified.
The (Precision/Recall/F1) metrics would penalize the model twice, once as a false-positive (for having picked an incorrect entitiy name), and again as a false-negative (for not having picked the actual entitiy name).
However, we notice that our system actually picked \(3/4\)ths of the actual entity name to be recognized. - This leads us seeking an evaluation metric that awards partial credit for this task.
- Consider the following text:
-
- The MUC Scorer is one, such, metric for giving partial credit.
- Albeit such complications and issues with the metrics described above, the field has, unfortunately, continued using the F1-Score as a metric for NER systems due to the complexity of formulating a metric that gives partial credit.
Sequence Models for Named Entity Recognition
-
- Approach:
-
- Training:
- Collect a set of representative training documents
- Label each token for its entity class or other (O)
- Design feature extractors appropriate to the text and classes
- Train a sequence classifier to predict the labels from the data
- Training:
-
- Testing:
- Receive a set of testing documents
- Run sequence model inference to label each token
- Appropriately output the recognized entities
- Testing:
-
- Encoding Classes for Sequence Labeling:
- There are two common ways to encode the classes:
- IO Encoding: this encoding will only encode only the entitiy of the token disregarding its order/position in the text (PER).
- For \(C\) classes, IO produces (\(C+1\) ) labels.
- IOB Encoding: this encoding is similar to IO encoding, however, it, also, keeps track to whether the token is the beginning of an entitiy-name (B-PER) or a continuation of such an entity-name (I-PER).
- For \(C\) classes, IO produces (\(2C+1\) ) labels.
- IO Encoding: this encoding will only encode only the entitiy of the token disregarding its order/position in the text (PER).
- The IO encoding, thus, is much lighter, and thus, allows the algorithm to run much faster than the IOB encoding.
Moreover, in practice, the issue presented for IO encoding rarely occurs and is only limited to instances where the entities that occur next to each other, are the same entity.
IOB encoded systems, also, tend to not learn quite as well due to the huge number of labels and are usually still prone to the same issues - Thus, due to the reasons mentioned above, the IO Encoding scheme is the one most commonly used.
-
- Features for Sequence Labeling:
-
- Words:
- Current word (like a learned dictionary)
- Previous/Next word (context)
- Other kinds of Inferred Linguistic Classification:
- Part-of-Speech Tags (POS-Tags)
- Label-Context:
- Previous (and perhaps next) label
This is usually what allows for sequence modeling
- Previous (and perhaps next) label
- Words:
- Other useful features:
- Word Substrings: usually there are substrings in words that are categorical in nature
- Examples:
“oxa” -> Drug
“(noun): (noun)” -> Movie
“(noun)-field” -> (usually) place
- Examples:
- Word Shapes: the idea is to map words to simplified representations that encode attributes such as:
length, capitalization, numerals, Greek-Letters, internal punctuation, etc.-
Example:
The representation below shows only the first two letters and the last two letters; for everything else, it will add the capitalization and the special characters, and for longer words, it will represent them in set notation.Varicella-zoster Xx-xxx mRNA xXXX CPA1 XXXd
-
- Word Substrings: usually there are substrings in words that are categorical in nature
Maximum Entropy Sequence Models
-
- Maximum-Entropy (Conditional) Markov Model:
- is a discriminative graphical model for sequence labeling that combines features of hidden Markov models (HMMs) and maximum entropy (MaxEnt) models.
- It is a discriminative model that extends a standard maximum entropy classifier by assuming that the unknown values to be learned are connected in a Markov chain rather than being conditionally independent of each other.
- It makes a single decision at a time, conditioned on evidence from observations and previous decisions.
-
A larger space of sequences is usually explored via search.
-
Inference:
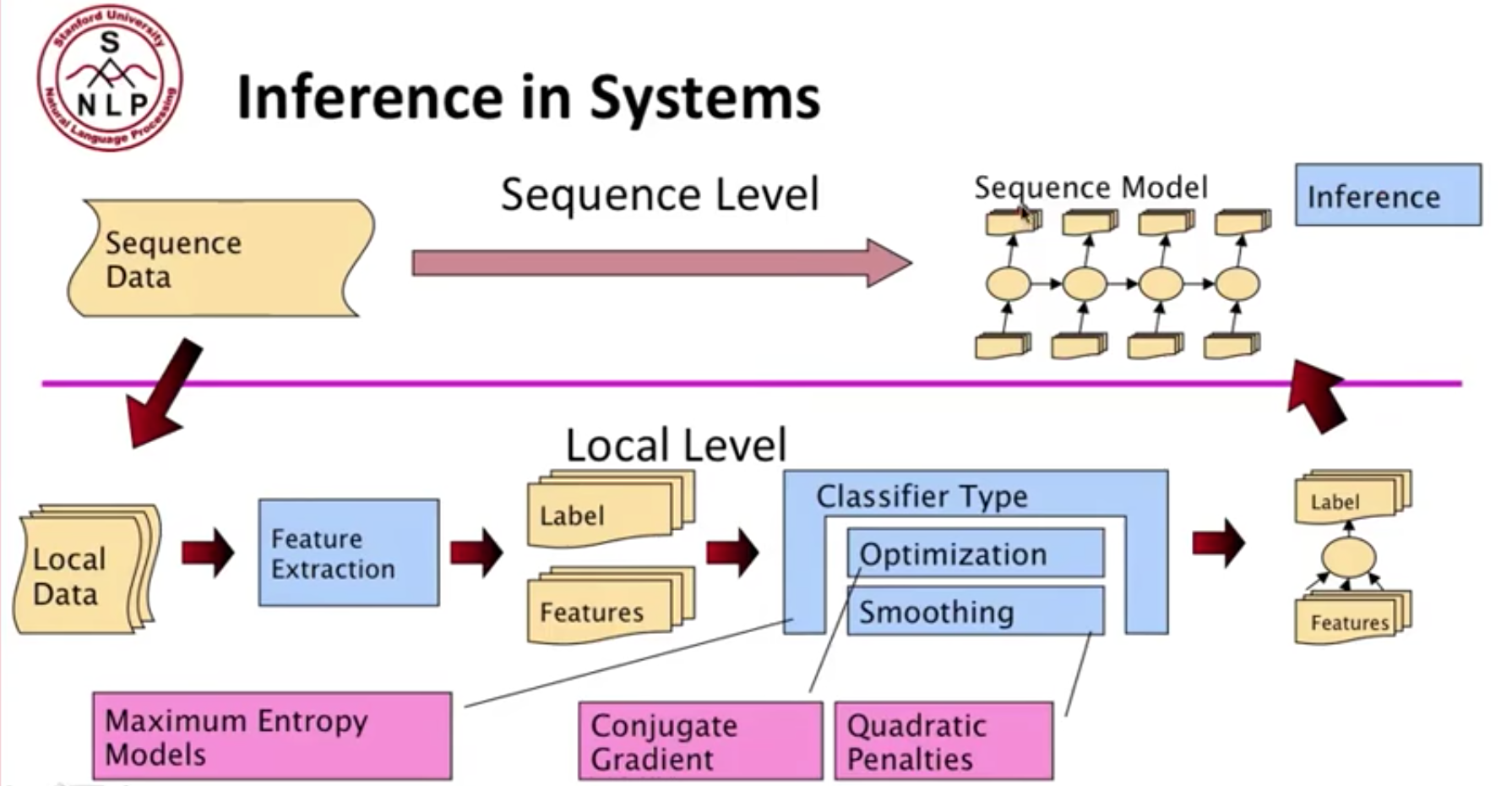
-
- Exploring the Sequence Space (Search Methods):
-
- Beam Inference:
- Algorithm:
- At each position keep the top \(k\) complete sequences.
- Extend each sequence in each local way.
- The extensions compete for the \(k\) slots at the next position.
- Advantages:
- Fast. Beam sizes of 3-5 are almost as good as exact inference in many cases.
- Easy. Implementation does not require dynamic programming.
- Disadvantages:
- Inexact. The globally best sequence can fall off the beam.
- Algorithm:
- Beam Inference:
-
- Viterbi Inference:
- Algorithm:
- Dynamic Programming or Memoization.
- Requires small window of state influence (eg. past two states are relevant)
- Advantages:
- Exact. the global best sequence is returned.
- Disadvantages:
- Hard. Harder to implement long-distance state-state interactions.
- Algorithm:
- Viterbi Inference:
-
- Conditional Random Fields (CRFs):
- are a type of discriminative undirected probabilistic graphical model.
- They can take context into account; and are commonly used to encode known relationships between observations and construct consistent interpretations.