Gradient-Based Optimization
-
Define Gradient Methods:
- Give examples of Gradient-Based Algorithms:
- What is Gradient Descent:
- Explain it intuitively:
- Give its derivation:
- What is the learning rate?
- Where does it come from?
- How does it relate to the step-size?
- We go from having a fixed step-size to [blank]:
- How do we choose the learning rate?
- Compare Line Search vs Trust Region:
- Describe the convergence of the algorithm:
-
How does GD relate to Euler?
- List the variants of GD:
- How do they differ?:
- BGD:
- SGD:
- How should we handle the lr in this case? Why?
- What conditions guarantee convergence of SGD?
- M-BGD:
- What advantages does it have?
- Explain the different kinds of gradient-descent optimization procedures:
- Batch Gradient Descent AKA Vanilla Gradient Descent, computes the gradient of the objective wrt. the parameters \(\theta\) for the entire dataset:
$$\theta=\theta-\epsilon \cdot \nabla_{\theta} J(\theta)$$
- SGD performs a parameter update for each data-point:
$$\theta=\theta-\epsilon \cdot \nabla_{\theta} J\left(\theta ; x^{(i)} ; y^{(i)}\right)$$
- Mini-batch Gradient Descent a hybrid approach that perform updates for a, pre-specified, mini-batch of \(n\) training examples:
$$\theta=\theta-\epsilon \cdot \nabla_{\theta} J\left(\theta ; x^{(i : i+n)} ; y^{(i : i+n)}\right)$$
- Batch Gradient Descent AKA Vanilla Gradient Descent, computes the gradient of the objective wrt. the parameters \(\theta\) for the entire dataset:
- State the difference between SGD and GD?
Gradient Descent’s cost-function iterates over ALL training samples.
Stochastic Gradient Descent’s cost-function only accounts for ONE training sample, chosen at random. - When would you use GD over SDG, and vice-versa?
GD theoretically minimizes the error function better than SGD. However, SGD converges much faster once the dataset becomes large.
That means GD is preferable for small datasets while SGD is preferable for larger ones.
- What is the problem of vanilla approaches to GD?
- List the challenges that account for the problem above:
- List the different strategies for optimizing GD:
- List the different variants for optimizing GD:
- Momentum:
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Nesterov Accelerated Gradient (Momentum):
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Successful Applications:
- Adagrad
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Successful Application:
- Properties:
- Adadelta
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Properties:
- RMSprop
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Properties:
- Adam
- Motivation:
- Definitions/Algorithm:
- Intuition:
- Parameter Settings:
- Properties:
- Which methods have trouble with saddle points?
- How should you choose your optimizer?
- Summarize the different variants listed above. How do they compare to each other?
-
What’s a common choice in many research papers?
- List additional strategies for optimizing SGD:
Maximum Margin Classifiers
- Define Margin Classifiers:
- What is a Margin for a linear classifier?
- Give the motivation for margin classifiers:
- Define the notion of the “best” possible classifier
- How can we achieve the “best” classifier?
- What unique vector is orthogonal to the hp? Prove it:
- What do we mean by “signed distance”? Derive its formula:
- Given the formula for signed distance, calculate the “distance of the point closest to the hyperplane”:
- Use geometric properties of the hp to Simplify the expression for the distance of the closest point to the hp, above
- Characterize the margin, mathematically:
- Characterize the “Slab Existence”:
- Formulate the optimization problem of maximizing the margin wrt analysis above:
- Reformulate the optimization problem above to a more “friendly” version (wrt optimization -> put in standard form):
- Give the final (standard) formulation of the “Optimization problem for maximum margin classifiers”:
- What kind of formulation is it (wrt optimization)? What are the parameters?
Hard-Margin SVMs
- Define:
- SVMs:
- Support Vectors:
- Hard-Margin SVM:
- Define the following wrt hard-margin SVM:
- Goal:
- Procedure:
- Decision Function:
- Constraints:
- The Optimization Problem:
- The Optimization Method:
- Elaborate on the generalization analysis:
- List the properties:
- Give the solution to the optimization problem for H-M SVM:
- What method does it require to be solved:
- Formulate the Lagrangian:
- Optimize the objective for each variable:
- Get the Dual Formulation w.r.t. the (tricky) constrained variable \(\alpha_n\):
- Set the problem as a Quadratic Programming problem:
- What are the inputs and outputs to the Quadratic Program Package?
- Give the final form of the optimization problem in standard form:
Soft-Margin SVM
- Motivate the soft-margin SVM:
- What is the main idea behind it?
- Define the following wrt soft-margin SVM:
- Goal:
- Procedure:
- Decision Function:
- Constraints:
- Why is there a non-negativity constraint?
- Objective/Cost Function:
- The Optimization Problem:
- The Optimization Method:
- Properties:
- Specify the effects of the regularization hyperparameter \(C\):
- Describe the effect wrt over/under fitting:
- How do we choose \(C\)?
- Give an equivalent formulation in the standard form objective for function estimation (what should it minimize?)
Loss Functions
- Define:
- Loss Functions:
- Distance-Based Loss Functions:
- Describe an important property of dist-based losses:
- What are they used for?
- Relative Error - What does it lack?
- List 3 Regression Loss Functions
- MSE
- What does it minimize:
- Formula:
- Graph:
- Derivation:
- MAE
- What does it minimize:
- Formula:
- Graph:
- Derivation:
- List properties:
- Huber Loss
- AKA:
- Formula:
- Graph:
- Derivation:
- List properties:
- Analyze MSE vs MAE:
- List 7 Classification Loss Functions
- \(0-1\) loss
- What does it minimize:
- Formula:
- Graph:
- MSE
- Formula:
- Graph:
- Derivation (for classification) - give assumptions:
- Properties:
- Hinge Loss
- What does it minimize:
- Formula:
- Graph:
- Describe the Properties of the Hinge loss and why it is used?
- Logistic Loss
- AKA:
- What does it minimize:
- Formula:
- Graph:
- Derivation:
- Properties:
- Cross-Entropy
- What does it minimize:
- Formula:
- Binary Cross-Entropy:
- Graph:
- CE and Negative-Log-Probability:
- CE and Log-Loss:
- Derivation:
- CE and KL-Div:
- Exponential Loss
- Formula:
- Properties:
- Perceptron Loss
- Formula:
- Analysis
- Logistic vs Hinge Loss:
- Cross-Entropy vs MSE:
Information Theory
- What is Information Theory? In the context of ML?
- Describe the Intuition for Information Theory. Intuitively, how does the theory quantify information (list)?
- Measuring Information - Definitions and Formulas:
- In Shannons Theory, how do we quantify “transmitting 1 bit of information”?
- What is the amount of information transmitted?
- What is the uncertainty reduction factor?
- What is the amount of information in an event \(x\)?
- Define the Self-Information:
- What is it defined with respect to?
- Define Shannon Entropy - what is it used for?
- Describe how Shannon Entropy relate to distributions with a graph:
- Define Differential Entropy:
- How does entropy characterize distributions?
- Define Relative Entropy:
- Give an interpretation:
- List the properties:
- Describe it as a distance:
- List the applications of relative entropy:
- How does the direction of minimization affect the optimization:
- Define Cross Entropy:
- What does it measure?
- How does it relate to relative entropy?
- When are they equivalent (wrt. optimization)?
- Mutual Information:
- Definition:
- What does it measure?
- Intuitive Definitions:
- Interpretations XXX:
- Properties:
- Applications:
- As KL-Divergence:
- In-terms of PMFs for discrete distributions:
- In terms of PDFs for continuous distributions:
- Relation to PMI:
- Pointwise Mutual Information (PMI):
- Definition:
- Relation to MI:
Recommendation Systems
- Describe the different algorithms for recommendation systems:
Ensemble Learning
- What are the two paradigms of ensemble methods?
- Random Forest VS GBM?
Data Processing and Analysis
- What are 3 data preprocessing techniques to handle outliers?
- Describe the strategies to dimensionality reduction:
- What are 3 ways of reducing dimensionality?
- List methods for Feature Selection
- List methods for Feature Extraction
- How to detect correlation of “categorical variables”?
- Feature Importance
- Capturing the correlation between continuous and categorical variable? If yes, how?
- What cross validation technique would you use on time series data set?
- How to deal with missing features? (Imputation?)
- Do you suggest that treating a categorical variable as continuous variable would result in a better predictive model?
- What are collinearity and multicollinearity?
- What is data normalization and why do we need it?
ML/Statistical Models
- What are parametric models?
- What is a classifier?
K-NN
PCA
- What is PCA?
- What is the Goal of PCA?
- List the applications of PCA:
- Give formulas for the following:
- Assumptions on \(X\):
- SVD of \(X\):
- Principal Directions/Axes:
- Principal Components (scores):
- The \(j\)-th principal component:
- Describe how to find the principal components:
- Define the transformation, mathematically:
- What does PCA produce/result in?
- Finds a lower dimensional subspace spanned by what?:
- Finds a lower dimensional subspace that minimizes what?:
- What does each PC have (properties)?
- What does the procedure find in terms of a “basis”?
- What does the procedure find in terms of axes? (where do they point?):
- Describe the PCA algorithm:
- What Data Processing needs to be done?
- How to compute the Principal Components?
- How do you compute the Low-Rank Approximation Matrix \(X_k\)?
- Describe the Optimality of PCA:
- List limitations of PCA:
- Intuition:
- What property of the internal structure of the data does PCA reveal/explain?
- What object does it fit to the data?:
- How does PCA relate to CCA?
- How does PCA relate to ICA?
- Should you remove correlated features b4 PCA?
- How can we measure the “Total Variance” of the data?
- How can we measure the “Total Variance” of the projected data?
- How can we measure the “Error in the Projection”?
- What does it mean when this ratio is high?
The Centroid Method
- Define “The Centroid”:
- Describe the Procedure:
- What is the Decision Function:
- Describe the Decision Boundary:
K-Means
- What is K-Means?
- What is the idea behind K-Means?
- What does K-Mean find?
- Formal Description of the Model:
- What is the Objective?
- Description of the Algorithm:
- What is the Optimization method used? What class does it belong to?
- How does the optimization method relate to EM?
- What is the Complexity of the algorithm?
- Describe the convergence and prove it:
- Describe the Optimality of the Algorithm:
- Derive the estimated parameters of the algorithm:
- Objective Function:
- Optimization Objective:
- Derivation:
- When does K-Means fail to give good results?
Naive Bayes
- Define:
- Naive Bayes:
- Naive Bayes Classifiers:
- Bayes Theorem:
- List the assumptions of Naive Bayes:
- List some properties of Naive Bayes:
- Is it a Bayesian Method or Frequentest Method?
- Is it a Bayes Classifier? What does that mean?:
- Define the Probabilistic Model for the method:
- What kind of model is it?
- What is a conditional probability model?
- Decompose the conditional probability w/ Bayes Theorem:
- How does the new expression incorporate the joint probability model?
- Use the chain rule to re-write the joint probability model:
- Use the Naive Conditional Independence assumption to rewrite the joint model:
- What is the conditional distribution over the class variable \(C_k\):
- Construct the classifier. What are its components? Formally define it.
- What’s the decision rule used?
- List the difference between the Naive Bayes Estimate and the MAP Estimate:
- What are the parameters to be estimated for the classifier?:
- What method do we use to estimate the parameters?:
- What are the estimates for each of the following parameters?:
- The prior probability of each class:
- The conditional probability of each feature (word) given a class:
CNNs
- What is a CNN?
- What are the layers of a CNN?
- What are the four important ideas and their benefits that the convolution affords CNNs:
- What is the inspirational model for CNNs:
- Describe the connectivity pattern of the neurons in a layer of a CNN:
- Describe the process of a ConvNet:
- Convolution Operation:
- Define:
- Formula (continuous):
- Formula (discrete):
- Define the following:
- Feature Map:
- Does the operation commute?
- Cross Correlation:
- Define:
- Formulae:
- What are the differences/similarities between convolution and cross-correlation:
- Write down the Convolution operation and the cross-correlation over two axes and:
- Convolution:
- Convolution (commutative):
- Cross-Correlation:
- The Convolutional Layer:
- What are the parameters and how do we choose them?
- Describe what happens in the forward pass:
- What is the output of the forward pass:
- How is the output configured?
- Spatial Arrangements:
- List the Three Hyperparameters that control the output volume:
- How to compute the spatial size of the output volume?
- How can you ensure that the input & output volume are the same?
- In the output volume, how do you compute the \(d\)-th depth slice:
- Calculate the number of parameters for the following config:
Given:
1. Input Volume: \(64\times64\times3\)
1. Filters: \(15 7\times7\)
1. Stride: \(2\)
1. Pad: \(3\) - Definitions:
- Receptive Field:
- Suppose the input volume has size \([ 32 × 32 × 3 ]\) and the receptive field (or the filter size) is \(5 × 5\) , then each neuron in the Conv Layer will have weights to a __Blank__ region in the input volume, for a total of __Blank__ weights:
- How can we achieve the greatest reduction in the spatial dims of the network (for classification):
- Pooling Layer:
- Define:
- List key ideas/properties and benefits:
- List the different types of Pooling:
Answer - List variations of pooling and their definitions:
- What is “Learned Pooling”:
- What is “Dynamical Pooling”:
- List the hyperparams of Pooling Layer:
- How to calculate the size of the output volume:
- How many parameters does the pooling layer have:
- What are other ways to perform downsampling:
- Weight Priors:
- Define “Prior Prob Distribution on the parameters”:
- Define “Weight Prior” and its types/classes:
- Weak Prior:
- Strong Prior:
- Infinitely Strong Prior:
- Describe the Conv Layer as a FC Layer using priors:
- What are the key insights of using this view:
- When is the prior imposed by convolution INAPPROPRIATE:
- What happens when the priors imposed by convolution and pooling are not suitable for the task?
- What kind of other models should Convolutional models be compared to? Why?:
- When do multi-channel convolutions commute?
Answer - Why do we use several different kernels in a given conv-layer?
- Strided Convolutions
- Define:
- What are they used for?
- What are they equivalent to?
- Formula:
- Zero-Padding:
- Definition/Usage:
- List the types of padding:
- Locally Connected Layers/Unshared Convolutions:
- Bias Parameter:
- How many bias terms are used per output channel in the tradional convolution:
- Dilated Convolutions
- Define:
- What are they used for?
- Stacked Convolutions
- Define:
- What are they used for?
- What is the rule of Bias(es) in CNNs:
Theory
RNNs
- What is an RNN?
- Definition:
- What machine-type is the standard RNN:
- What is the big idea behind RNNs?
- Dynamical Systems:
- Standard Form:
- RNN as a Dynamical System:
- Unfolding Computational Graphs
- Definition:
- List the Advantages introduced by unfolding and the benefits:
- Graph and write the equations of Unfolding hidden recurrence:
- Describe the State of the RNN, its usage, and extreme cases of the usage:
- RNN Architectures:
- List the three standard architectures of RNNs:
- Graph:
- Architecture:
- Equations:
- Total Loss:
- Complexity:
- Properties:
- List the three standard architectures of RNNs:
- Teacher Forcing:
- Definition:
- Application:
- Disadvantages:
- Possible Solutions for Mitigation:
Optimization
- Define the sigmoid function and some of its properties:
- Backpropagation:
- Definition:
- Derive Gradient Descent Update:
- Explain the difference kinds of gradient-descent optimization procedures:
- List the different optimizers and their properties:
- Error-Measures:
- Define what an error measure is:
- List the 5 most common error measures and where they are used:
- Specific Questions:
- Derive MSE carefully:
- Derive the Binary Cross-Entropy Loss function:
- Explain the difference between Cross-Entropy and MSE and which is better (for what task)?
- Describe the properties of the Hinge loss and why it is used?
- Show that the weight vector of a linear signal is orthogonal to the decision boundary?
- What does it mean for a function to be well-behaved from an optimization pov?
- Write \(\|\mathrm{Xw}-\mathrm{y}\|^{2}\) as a summation
- Compute:
- \(\dfrac{\partial}{\partial y}\vert{x-y}\vert=\)
- State the difference between SGD and GD?
- When would you use GD over SDG, and vice-versa?
- What is convex hull ?
- OLS vs MLE
ML Theory
- Explain intuitively why Deep Learning works?
- List the different types of Learning Tasks and their definitions:
answer - Describe the relationship between supervised and unsupervised learning?
answer - Describe the differences between Discriminative and Generative Models?
- Describe the curse of dimensionality and its effects on problem solving:
- How to deal with curse of dimensionality
- Describe how to initialize a NN and any concerns w/ reasons:
- Describe the difference between Learning and Optimization in ML:
- List the 12 Standard Tasks in ML:
- What is the difference between inductive and deductive learning?
Statistical Learning Theory
- Define Statistical Learning Theory:
- What field is it the theory for?:
- What fields does it draw from?:
- What does it allow us to do?:
- What question does it answer?:
- What is it a subfield-of/approach-to?:
- What assumptions are made by the theory?
- Define the i.i.d assumptions?
- Why assume a joint probability distribution \(p(x,y)\)?
- Why do we need to model \(y\) as a target-distribution and not a target-function?
- Give the Formal Definition of SLT:
- The Definitions:
- The Assumptions:
- The Inference Problem:
- The Expected Risk:
- The Target Function:
- The Empirical Risk:
- Define Empirical Risk Minimization:
- What is the Complexity of ERM?
- How do you Cope with the Complexity?
- Definitions:
- Generalization:
- Generalization Error:
- Generalization Gap:
- Computing the Generalization Gap:
- What is the goal of SLT in the context of the Generalization Gap given that it can’t be computed?
- Achieving (“good”) Generalization:
An algorithm is said to generalize when - Empirical Distribution:
- Describe the difference between Learning and Optimization in ML:
- Describe the difference between Generalization and Learning in ML:
- How to achieve Learning?
- What does the (VC) Learning Theory Achieve?
- Why do we need the probabilistic framework?
- Give the Formal Definition of SLT:
- What is the Approximation-Generalization Tradeoff? How is it characterized?:
- What are the factors determining how well an ML-algo will perform?
- Define the following and their usage/application & how they relate to each other:
- Underfitting:
- Overfitting:
- Capacity:
- Models with Low-Capacity:
- Models with High-Capacity:
- Hypothesis Space:
- VC-Dimension:
- What does it measure?
- Graph the relation between Error, and Capacity in the ctxt of (Underfitting, Overfitting, Training Error, Generalization Err, and Generalization Gap):
- What is the most important result in SLT that show that learning is feasible?
Bias-Variance Decomposition Theory
- What is the Bias-Variance Decomposition Theory:
- What are the Assumptions made by the theory?
- What is the question that the theory tries to answer? How do you achieve the answer to this question? What assumption is important?
- What is the Bias-Variance Decomposition:
- Define each term w.r.t. source of the error (error from):
- Bias:
- Variance:
- Irreducible Error:
- What does each of the following measure (error in)? Describe this measured quantity in words, mathematically. Describe Bias&Variance in Words as a question statement. Give their AKA in statistics.
- Bias:
- Variance:
- Irreducible Error:
- Give the Formal Definition of the Decomposition (Formula):
- What is the Expectation over?
- Define the Bias-Variance Tradeoff:
- Effects of Bias:
- High Bias:
- Low Bias:
- Effects of Variance:
- High Variance:
- Low Variance:
- Draw the Graph of the Tradeoff (wrt model capacity):
- Effects of Bias:
- Derive the Bias-Variance Decomposition with explanations:
- What are the key Takeaways from the Tradeoff?
- What are the most common ways to negotiate the Tradeoff? (i.e. selecting/comparing models)
- How does the decomposition relate to Classification?
- Increasing/Decreasing Bias&Variance:
- Adding Good Feature:
- Adding Bad Feature:
- Adding ANY Feature:
- Adding more Data:
- Noise in Test Set:
- Noise in Training Set:
- Dimensionality Reduction:
- Feature Selection:
- Regularization:
- Increasing # of Hidden Units in ANNs:
- Increasing # of Hidden Layers in ANNs:
- Increasing \(k\) in K-NN:
- Increasing Depth in Decision-Trees:
- Boosting:
- Bagging:
Activation Functions
- Describe the Desirable Properties for activation functions:
- Non-Linearity:
- Range:
- Continuously Differentiable:
- Monotonicity:
- Smoothness with Monotonic Derivatives:
- Approximating Identity near Origin:
- Zero-Centered Range:
- Describe the NON-Desirable Properties for activation functions:
- Saturation:
- Vanishing Gradients:
- Range Not Zero-Centered:
- List the different activation functions used in ML?
Names, Definitions, Properties (pros&cons), Derivatives, Applications, pros/cons:
- Fill in the following table:
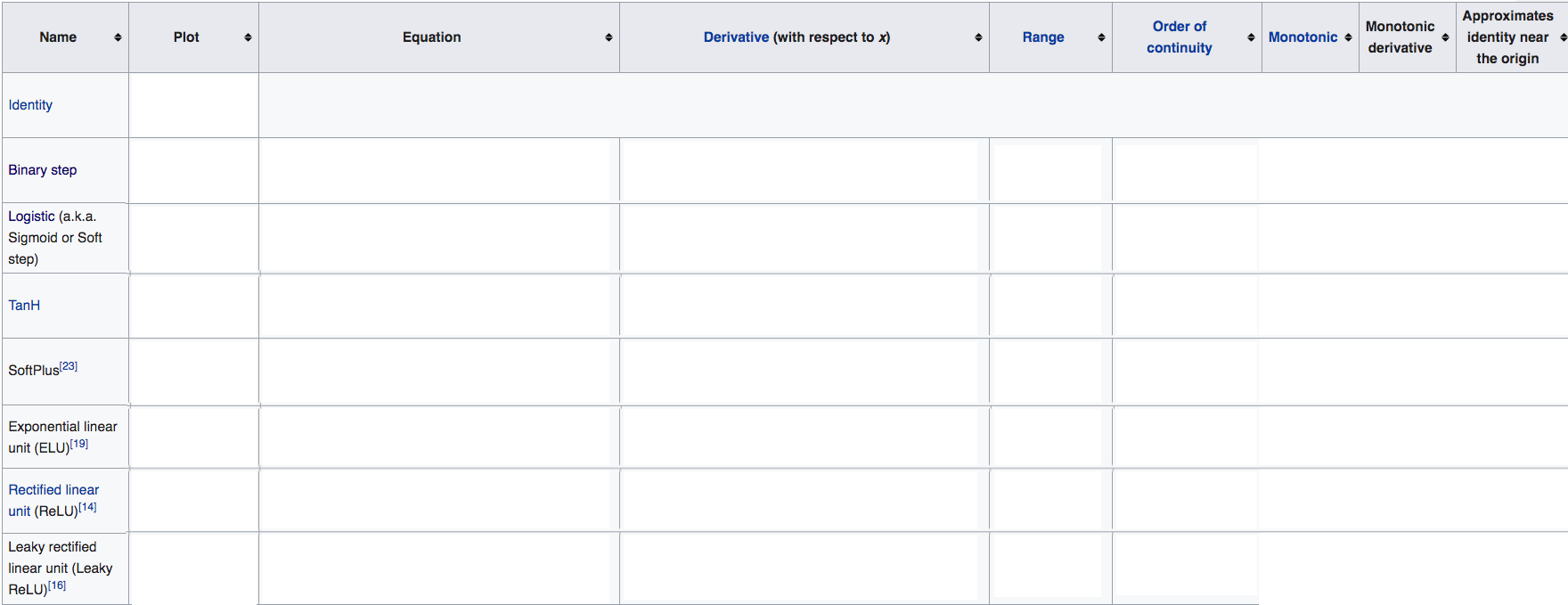
- Tanh VS Sigmoid for activation?
- ReLU:
- What makes it superior/advantageous?
- What problems does it have?
- What solution do we have to mitigate the problem?
- Compute the derivatives of all activation functions:
- Graph all activation functions and their derivatives:
Kernels
- Define “Local Kernel” and give an analogy to describe it:
- Write the following kernels:
- Polynomial Kernel of degree, up to, \(d\):
- Gaussian Kernel:
- Sigmoid Kernel:
- Polynomial Kernel of degree, exactly, \(d\):
Math
-
What is a metric?
Metric -
Describe Binary Relations and their Properties?
answer - Formulas:
- Set theory:
- Number of subsets of a set of \(N\) elements:
- Number of pairs \((a,b)\) of a set of N elements:
- Binomial Theorem:
- Binomial Coefficient:
- Expansion of \(x^n - y^n =\)
- Number of ways to partition \(N\) data points into \(k\) clusters:
- \(\log_x(y) =\)
- The length of a vector \(\mathbf{x}\) along a direction (projection):
- Along a unit-length vector \(\hat{\mathbf{w}}\):
- Along an unnormalized vector \(\mathbf{w}\):
- \(\sum_{i=1}^{n} 2^{i}=\)
- Set theory:
-
List 6 proof methods:
answer - Something
Statistics
- ROC curve:
- Definition:
- Purpose:
- How do you create the plot?
- How to identify a good classifier:
- How to identify a bad classifier:
- What is its application in tuning the model?
- AUC - AUROC:
- Definition:
- Range:
- What does it measure:
- Usage in ML:
- Define Statistical Efficiency (of an estimator)?
- Intuitive Difference:
- How do we define Efficiency?
- What’s the difference between an efficient and inefficient estimators?
- How’s the use of an inefficient estimator bad compared to an efficient one?
- Whats the difference between Errors and Residuals:
- Compute the statistical errors and residuals of the univariate, normal distribution defined as \(X_{1}, \ldots, X_{n} \sim N\left(\mu, \sigma^{2}\right)\):
- What is a biased estimator?
- Why would we prefer biased estimators in some cases?
- What is the difference between “Probability” and “Likelihood”:
- Estimators:
- Define:
- Formula:
- Whats a good estimator?
- What are the Assumptions made regarding the estimated parameter:
- What is Function Estimation:
- Whats the relation between the Function Estimator \(\hat{f}\) and Point Estimator:
- Define “marginal likelihood” (wrt naive bayes):
(Statistics) - MLE
- Clearly Define MLE and derive the final formula:
- Write MLE as an expectation wrt the Empirical Distribution:
- Describe formally the relationship between MLE and the KL-divergence:
- Extend the argument to show the link between MLE and Cross-Entropy. Give an example of a well-known loss function:
- How does the form of the model (model family) affect the MLE Estimate?
- How does MLE relate to the model distribution and the empirical distribution?
- What is the intuition behind using MLE?
- What does MLE find/result in?
- What kind of problem is MLE and how to solve for it?
- How does it relate to SLT:
- Explain clearly why we maximize the natural log of the likelihood
Text-Classification | Classical
- List some Classification Methods:
- List some Applications of Txt Classification:
NLP
- List some problems in NLP:
- List the Solved Problems in NLP:
- List the “within reach” problems in NLP:
- List the Open Problems in NLP:
- Why is NLP hard? List Issues:
- Define:
- Morphology:
- Morphemes:
- Stems:
- Affixes:
- Stemming:
- Lemmatization:
Language Modeling
- What is a Language Model?
- List some Applications of LMs:
- Traditional LMs:
- How are they setup?
- What do they depend on?
- What is the Goal of the LM task? (in the ctxt of the problem setup)
- What assumptions are made by the problem setup? Why?
- What are the MLE Estimates for probabilities of the following:
- Bi-Grams:
$$p(w_2\vert w_1) = $$
- Tri-Grams:
$$p(w_3\vert w_1, w_2) = $$
- Bi-Grams:
- What are the issues w/ Traditional Approaches?
- What+How can we setup some NLP tasks as LM tasks:
- How does the LM task relate to Reasoning/AGI:
- Evaluating LM models:
- List the Loss Functions (+formula) used to evaluate LM models? Motivate each:
- Which application of LM modeling does each loss work best for?
- Why Cross-Entropy:
- Which setting it used for?
- Why Perplexity:
- Which setting used for?
- If no surprise, what is the perplexity?
- How does having a good LM relate to Information Theory?
- LM DATA:
- How does the fact that LM is a time-series prediction problem affect the way we need to train/test:
- How should we choose a subset of articles for testing:
- List three approaches to Parametrizing LMs:
- Describe “Count-Based N-gram Models”:
- What distributions do they capture?:
- Describe “Neural N-gram Models”:
- What do they replace the captured distribution with?
- What are they better at capturing:
- Describe “RNNs”:
- What do they replace/capture?
- How do they capture it?
- What are they best at capturing:
- What’s the main issue in LM modeling?
- How do N-gram models capture/approximate the history?:
- How do RNNs models capture/approximate the history?:
- The Bias-Variance Tradeoff of the following:
- N-Gram Models:
- RNNs:
- An Estimate s.t. it predicts the probability of a sentence by how many times it has seen it before:
- What happens in the limit of infinite data?
- What are the advantages of sub-word level LMs:
- What are the disadvantages of sub-word level LMs:
- What is a “Conditional LM”?
- Write the decomposition of the probability for the Conditional LM:
- Describe the Computational Bottleneck for Language Models:
- Describe/List some solutions to the Bottleneck:
- Complexity Comparison of the different solutions:

Regularization
- Define Regularization both intuitively and formally:
- Define “well-posedness”:
- Give four aspects of justification for regularization (theoretical):
- From a philosophical pov:
- From a probabilistic pov:
- From an SLT pov:
- From a practical pov (relating to the real-world):
- Describe an overview of regularization in DL. How does it usually work?
- Intuitively, how can a regularizer be effective?
- Describe the relationship between regularization and capacity. How does regularization work in this case?
- Describe the different approaches to regularization:
- List 9 regularization techniques:
- Describe Parameter Norm Penalties (PNPs):
- Describe the parameter \(\alpha\):
- How does it influence the regularization:
- What is the effect of minimizing the regularized objective?
- How do we deal with the Bias parameter in PNPs? Explain.
- Describe the tuning of the \(\alpha\) HP in NNs for different hidden layers:
- Formally describe the \(L^2\) parameter regularization:
- AKA:
- Describe the regularization contribution to the gradient in a single step.
- Describe the regularization contribution to the gradient. How does it scale?
- How does weight decay relate to shrinking the individual weight wrt their size? What is the measure/comparison used?
- Draw a graph describing the effects of \(L^2\) regularization on the weights:
- Describe the effects of applying weight decay to linear regression
- Derivation:
- What is \(L^2\) regularization equivalent to?
- What are we maximizing?
- Derive the MAP Estimate:
- What kind of prior do we place on the weights? What are its parameters?
- List the properties of \(L^2\) regularization:
- Formally describe the \(L^1\) parameter regularization:
- AKA:
- Whats the regularized objective function?
- What is its gradient?
- Describe the regularization contribution to the gradient compared to L2. How does it scale?
- List the properties and applications of \(L^1\) regularization:
- How is used as a feature selection mechanism?
- Derivation:
- What is \(L^1\) regularization equivalent to?
- What kind of prior do we place on the weights? What are its parameters?
- Analyze \(L^1\) vs \(L^2\) regularization:
- For Sparsity:
- For correlated features:
- For optimization:
- Give an example that shows the difference wrt sparsity:
- For sensitivity:
- Describe Elastic Net Regularization. Why was it devised?
- Motivate Regularization for ill-posed problems:
- What is the property that needs attention?
- What would the regularized solution correspond to in this case?
- Are there any guarantees for the solution to be well-posed? How/Why?
- What is the Linear Algebraic property that needs attention?
- What models are affected by this?
- What would the sol correspond to in terms of inverting \(X^TX\):
- When would \(X^TX\) be singular?
- Describe the Linear Algebraic Perspective. What does it correspond to? [LAP]
- Can models with no closed-form solution be underdetermined? Explain. [CFS]
- What models are affected by this? [CFS]
- Define the Moore-Penrose Pseudoinverse:
- What can it solve?
- What does it correspond to in terms of regularization?
- What is the limit wrt?
- How can we interpret the pseudoinverse wrt regularization?
- Explain the problem with Logistic Regression:
- What are the possible solutions?
- Are there any guarantees that we achieve with regularization?
- Describe dataset augmentation and its techniques:
- When is dataset augmentation applicable?
- When is it not?
- Motivate Noise Robustness property:
- How can Noise Robustness motivate a regularization technique?
- How can we enhance noise robustness in NN?
- Where can noise be injected?
- Give Motivation, Interpretation and Applications of injecting noise in the different components (from above):
- Motivate the injecting of noise:
- Give an interpretation for injecting noise in the Input layer:
- Give an interpretation for injecting noise in the Hidden layers:
- What is the most successful application of this technique:
- Describe the Bayesian View of learning:
- How does it motivate injecting noise in the weight matrices?
- Describe a different interpretation of injecting noise to matrices. What are its effects on the function to be learned?
- Whats the biggest application for this kind of regularization?
- Motivate injecting noise in the Output layer:
- What is the biggest application of this technique?
- How does it compare to weight-decay when applied to MLE problems?
- Define “Semi-Supervised Learning”:
- What does it refer to in the context of DL:
- What is its goal?
- Give an example in classical ML:
- Describe an approach to applying semi-supervised learning:
- How can we interpret dropout wrt data augmentation?
- When is Ridge regression favorable over Lasso regression? for correlated features?
Misc.
- Explain Latent Dirichlet Allocation (LDA)
- How to deal with curse of dimensionality
- How to detect correlation of “categorical variables”?
- Define “marginal likelihood” (wrt naive bayes):
- KNN VS K-Means
- When is Ridge regression favorable over Lasso regression for correlated features?
- Capturing the correlation between continuous and categorical variable? If yes, how?
- Random Forest VS GBM?
- What is convex hull ?
- What cross validation technique would you use on time series data set?
- How to deal with missing features? (Imputation?)
- Describe the different algorithms for recommendation systems:
- Do you suggest that treating a categorical variable as continuous variable would result in a better predictive model?
- OLS vs MLE
- What is the difference between inductive and deductive learning?
- What are collinearity and multicollinearity?
- What are the two paradigms of ensemble methods?
- Describe Label Smoothing as a regularization technique:
- Give its motivation:
- What is data normalization and why do we need it?:
- Weight initialization in neural networks?:
- How to improve Generalization
- How to prevent Overfitting
- How to control the capacity
- Why small weights in NN lead to lower capacity:
- Give its motivation:
INTERVIEWS
- Can they derive the back-propagation and weights update?:
- Extend the above question to non-trivial layers such as convolutional layers, pooling layers, etc.:
- How to implement dropout:
- Their intuition when and why some tricks such as max pooling, ReLU, maxout, etc. work. There are no right answers but it helps to understand their thoughts and research experience.:
- Can they abstract the forward, backward, update operations as matrix operations, to leverage BLAS and GPU?:
- What is an auto-encoder? Why do we “auto-encode”? Hint: it’s really a misnomer.:
- What is a Boltzmann Machine? Why a Boltzmann Machine?:
- Why do we use sigmoid for an output function? Why tanh? Why not cosine? Why any function in particular?:
- Why are CNNs used primarily in imaging and not so much other tasks?:
- Explain backpropagation. Seriously. To the target audience described above.:
- Is it OK to connect from a Layer 4 output back to a Layer 2 input?:
- A data-scientist person recently put up a YouTube video explaining that the essential difference between a Neural Network and a Deep Learning network is that the former is trained from output back to input, while the latter is trained from input toward output. Do you agree? Explain.:
- Interview Qs (Quora)
- NLP-Interview
- Robin-Interview
- Robin
- CV-Inter
- Polarr-Inter
FeedForward Neural Network
- What is a “FeedForward” Neural Network:
- What is the Architecture of an FFN (components and how they work together):
- List two examples of FFNs:
- Describe the “Single-Layer Perceptron”:
- Describe the “Multi-Layer Perceptron” (vaguely describe the components of the architecture and how they fit together):
Multilayer Perceptron
- What model class does the “Multi-Layer Perceptron” belong to:
- What is the Architecture of an MLP:
- What are the Layers names/types:
- What do the Connections between the nodes represent:
- What else is important to make it multi-layer? why/motivation (biologically and mathematically)?
- Describe “Learning” of an MLP (Learning Algorithm and brief description of the procedure and optimization):
- List the properties of the MLP:
Deep Feedforward Neural Networks
- Describe the Deep Feedforward Neural Networks:
- As a “Classifier” (from what does it learn and what does it define?):
- What is its function?
- How does it model the targets? (describe the underlying model and what it learns)
- What does it learn?
- What is its goal (besides trying to approximate the function on the training data)?
- Why are they called “networks”/how are they represented?:
- How are the Functions composed together?
- How is this composition described?
- What is the common structure for connecting the functions (from layer to layer)?
- How do we define Depth:
- What does the Training Data provide? and how do we learn from it?
- Describe the Motivation for Deep FFNs:
- topic:
- How can we interpret Deep Neural Networks (in SLT):
AutoEncoders
- What is an AutoEncoder? What is its goal? (draw a diagram)
- What type of NN is the Autoencoder?
- Give Motivation for AutoEncoders:
- Why Deep AutoEncoders? What do they allow us to do?
- List the Advantages of Deep AutoEncoders:
- List the Applications of AutoEncoders:
- Describe the Training of Deep AutoEncoders:
- What are the challenges if any?
- What are the main methods for training Deep AutoEncoders?
- Which one is the most superior method?
- How is Joint Training better:
- Why is Joint Training better:
- Describe the Architecture of AutoEncoders:
- What is the simplest form of an AE:
- What realm of “Learning” is employed for AEs?
-
Mathematical Description of the Structure of AutoEncoders:
- How do we define the “Encoder” and “Decoder”?
- The Encoder maps what to what?
- The Decoder maps what to what?
- What is the type of loss?
- What are “Transition Functions”?
- Compare AutoEncoders and PCA (wrt what they learn):
- List the different Types of AEs
- How can we use AEs for Initialization?
- Describe the Representational Power of AEs:
- (wrt Layer Size and Depth):
- Why is Depth Important?
-
Describe the progression (stages) of AE Architectures in CV:
- What are Undercomplete AutoEncoders?
- What’s the motivation behind Undercomplete AEs?
- List the Challenges of Utilizing Undercomplete AEs:
- What is the Main Method/Approach of addressing the Challenges above (Training AEs)?
- Define Regularized Autoencoders:
- What does it allow us to do?
- How does it address the Challenges?
- What other Properties does it encourage to be learned?
- What kind of technique (also type) of AEs can be “non-linear” and still learn useful codes?
- What kind of technique-needed for (also type-of) AEs can be “overcomplete” and still learn useful codes?
- What kind of technique-needed for (also type-of) AEs can be “nonlinear” AND “overcomplete” and still learn useful codes?
- What are the ways to learn useful encodings/representations?
Defining an appropriate Objective and Objective Function.- What types of objectives help learn useful encodings/representations?
(regularized/approximate) Auto-Encoding - Maximizing the Probability of training Data (NLL)
Further Info
- What types of objectives help learn useful encodings/representations?
- Describe the Relationship between Generative Models and AEs:
- What are the components needed for the Generative Model?:
- What notable types? List:.
- Compare Generative Models & AEs in how they learn codings/representations:
- Why are their representations “naturally” useful?
- List the Different Types of Regularized Autoencoders:
- Define Sparse Autoencoders (w/ equation):
- How can we interpret Sparse AEs? (Hint: 3 interpretations)
- Give the “Regularization” Interpretation of Sparse AEs:
- Give the “Bayesian” Interpretation of Regularized AEs:
- Give the “Latent Variable” Interpretation of Sparse AEs:
- What do Sparse AEs approximate?
- How do they (does that) relate to MLE?
- Define Denoising Autoencoders:
- What do they minimize? (canonical loss)
- What do they learn? How? (compare)
- How do we generate the inputs?
- What does the “Corruption Process” represent/define?
- How do we generate the training examples (input-output pair)? (process)
- What does the Denoising AE learn specifically? (mathematically)
- What do we use as an estimate for the “Reconstruction Distribution”?
- What is the output of the encoder \(f\)?
- What is the output of the decoder \(g\)?
- What is the “Reconstruction Distribution” equal to?
- How do we Train the Denoising AE?
- What is the Loss?
- What is the Optimization Method?
- What is the Training similar to?
- Is the Encoder Deterministic?
- Would change if it was one or the other?
- How can we view the function of DAEs (wrt learning/training) from a Probabilistic pov?
- What Expectation is it minimizing? Over what?
- Can we re-write the Objective/Loss wrt the Empirical Distribution?
- What other ways exist for learning/training DAEs?
-
How do DAEs and VAEs relate to each other?
- Define Contractive Autoencoders
- What is the regularizer/penalty used?
- What does it encourage the system to do?
- How is the Contractive AE connected to the DAE:
- Why is the CAE called “Contractive”?
- Is it contractive locally or globally or both?
- Give the Interpretation of the CAE as a Linear Operator:
- List the Issues associated with using a “Contractive Penalty”: